Products
Customers
Developers
Resources
Company
AWS and Cerebras Collaboration Sets a New Standard for AI Inference Speed and Performance in the Cloud >
November 06, 2025
October 13, 2025
August 15, 2025
August 06, 2025
August 01, 2025
July 29, 2025
June 11, 2025
May 15, 2025
April 09, 2025
February 06, 2025
January 29, 2025
January 13, 2025
January 01, 2025
November 18, 2024
October 24, 2024
August 27, 2024
May 15, 2024
April 12, 2024
March 12, 2024
December 14, 2023
November 10, 2023
October 12, 2023
July 20, 2023
Follow
Get Updates
News
Insights
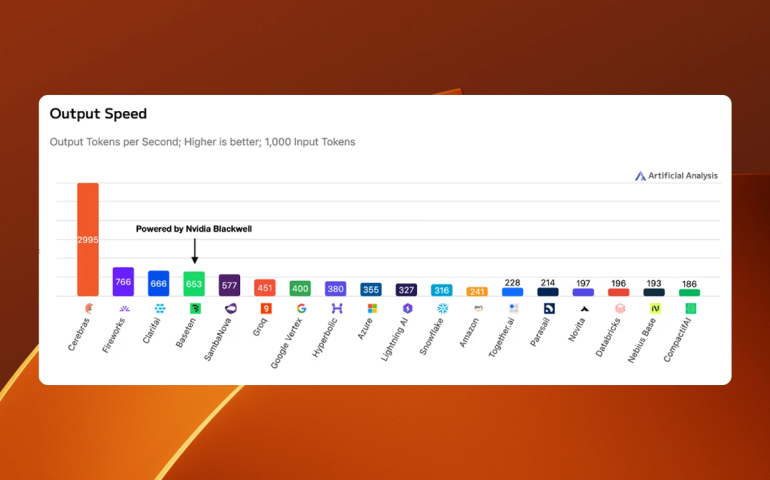
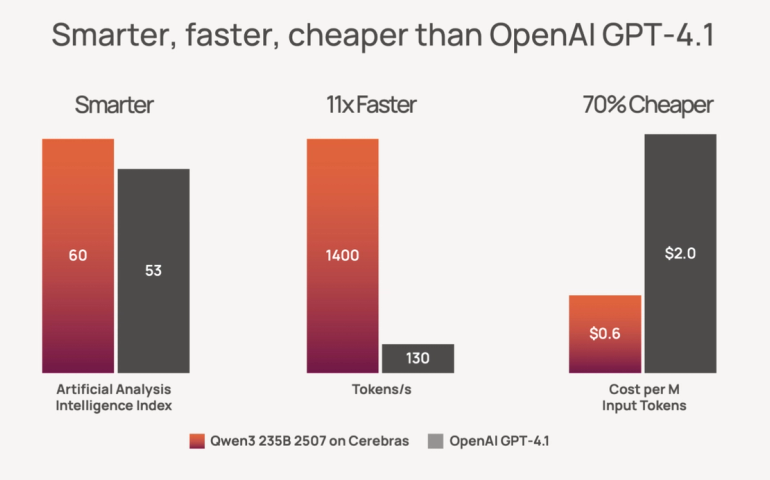
Performance comparisons are based on third-party benchmarking or internal testing. Observed inference speed improvements versus GPU-based systems may vary depending on workload, configuration, date and models being tested.
1237 E. Arques Ave Sunnyvale, CA 94085
© 2026 Cerebras. All rights reserved.