Frontier AI now runs at instant speed. Last week we ran a customer workload on Llama 3.1 405B at 969 tokens/s – a new record for Meta’s frontier model. Llama 3.1 405B on Cerebras is by far the fastest frontier model in the world – 12x faster than GPT-4o and 18x faster than Claude 3.5 Sonnet. In addition, we achieved the highest performance at 128K context length and shortest time-to-first-token latency, as measured by Artificial Analysis.
Llama 3.1 405B on Cerebras Inference highlights:
- 969 output tokens per second – 12x faster than best GPU result
- 240ms time to first token – a fraction of most APIs
- 128K context length support – highest recorded performance
- 16-bit weights – full model accuracy
- Q1 general availability at $6/M input tokens and $12/M output tokens
Frontier AI at Instant Speed
This year Cerebras pushed Llama 3.1 8B and 70B to over 2,000 tokens/s, but frontier models such as GPT-4o, Claude 3.5 Sonnet, and Llama 3.1 405B have never exceeded 200 tokens/s on any GPU, ASIC, or cloud. As a result, developers have had to choose between second tier models that run fast or frontier models that run slow. Cerebras Inference fixes this. Responding to a customer request to show Llama 3.1 405B on Cerebras Inference at full 128K context, we deployed a instance that broke every record in output speed, long context performance, and time-to-first-token as measured by Artificial Analysis.
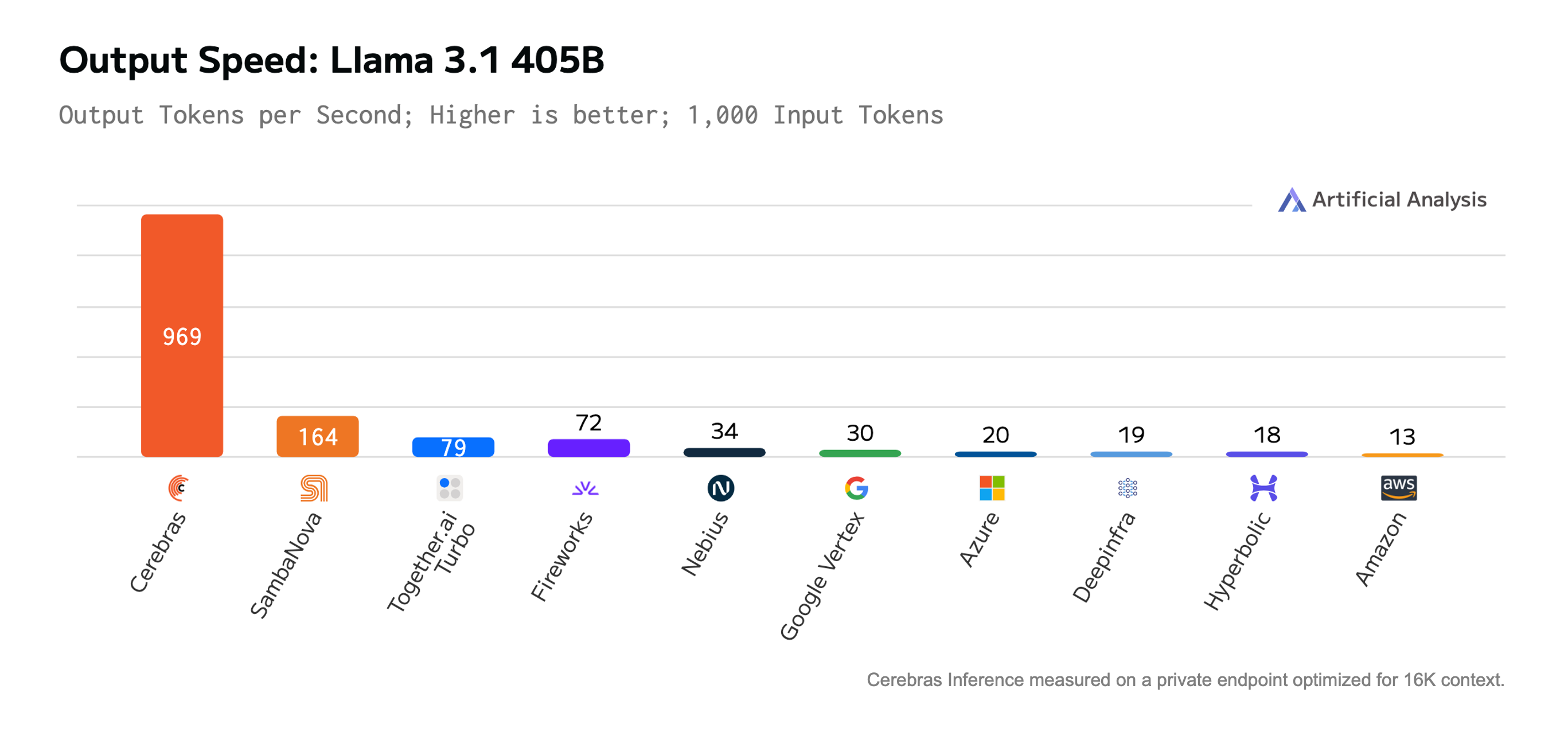
Cerebras Inference generated 969 output tokens/s when given a 1,000 token prompt. This is the first time a frontier model is running at instant speed, allowing entire pages of text, code, and math to be complete in a flash. This result was 8x faster than SambaNova, 12x faster than the fastest GPU cloud, and 75x faster than AWS.
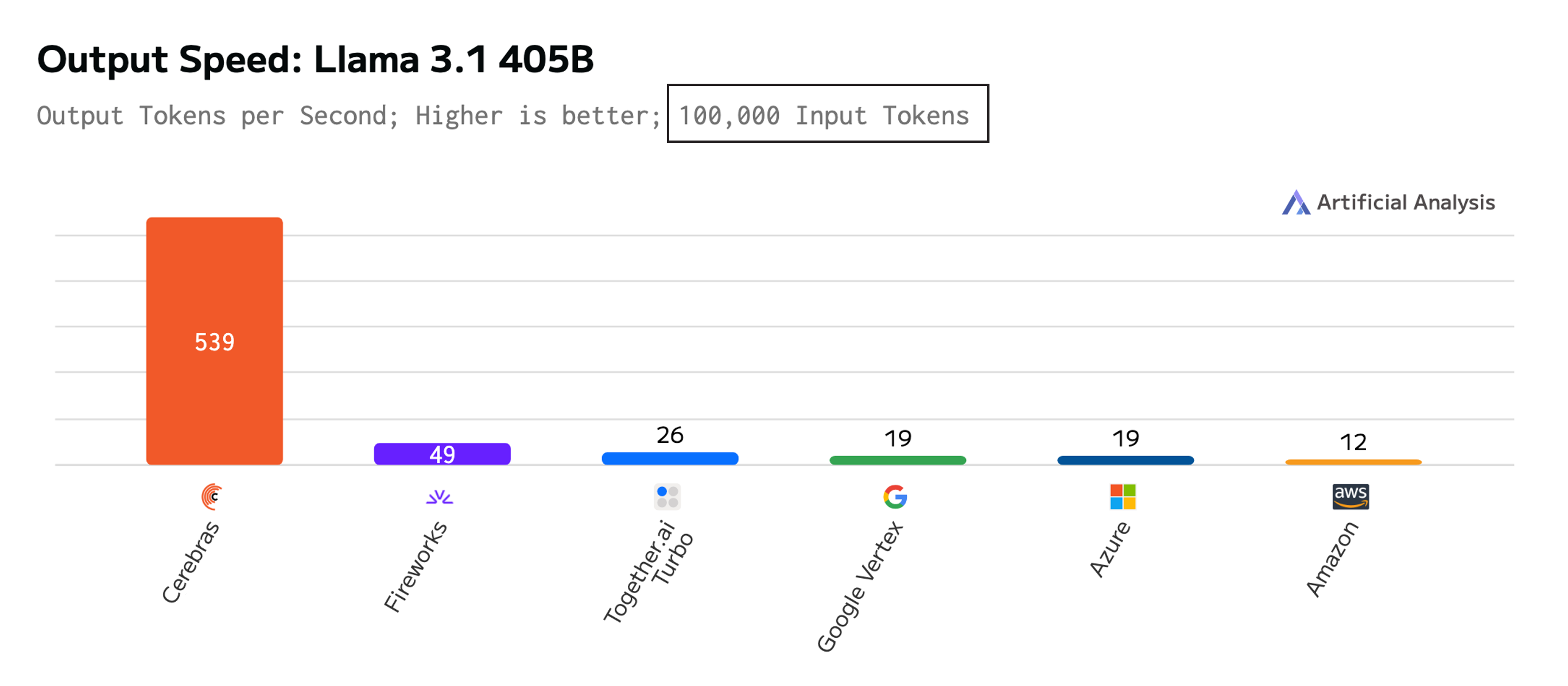
When the input prompt was extended to 100,000 tokens, only six vendors returned a result with Cerebras being the only non-GPU vendor to complete the benchmark. Cerebras achieved 539 tokens/s – 11x faster than Fireworks and 44x faster than AWS.
Best-in-Class Latency
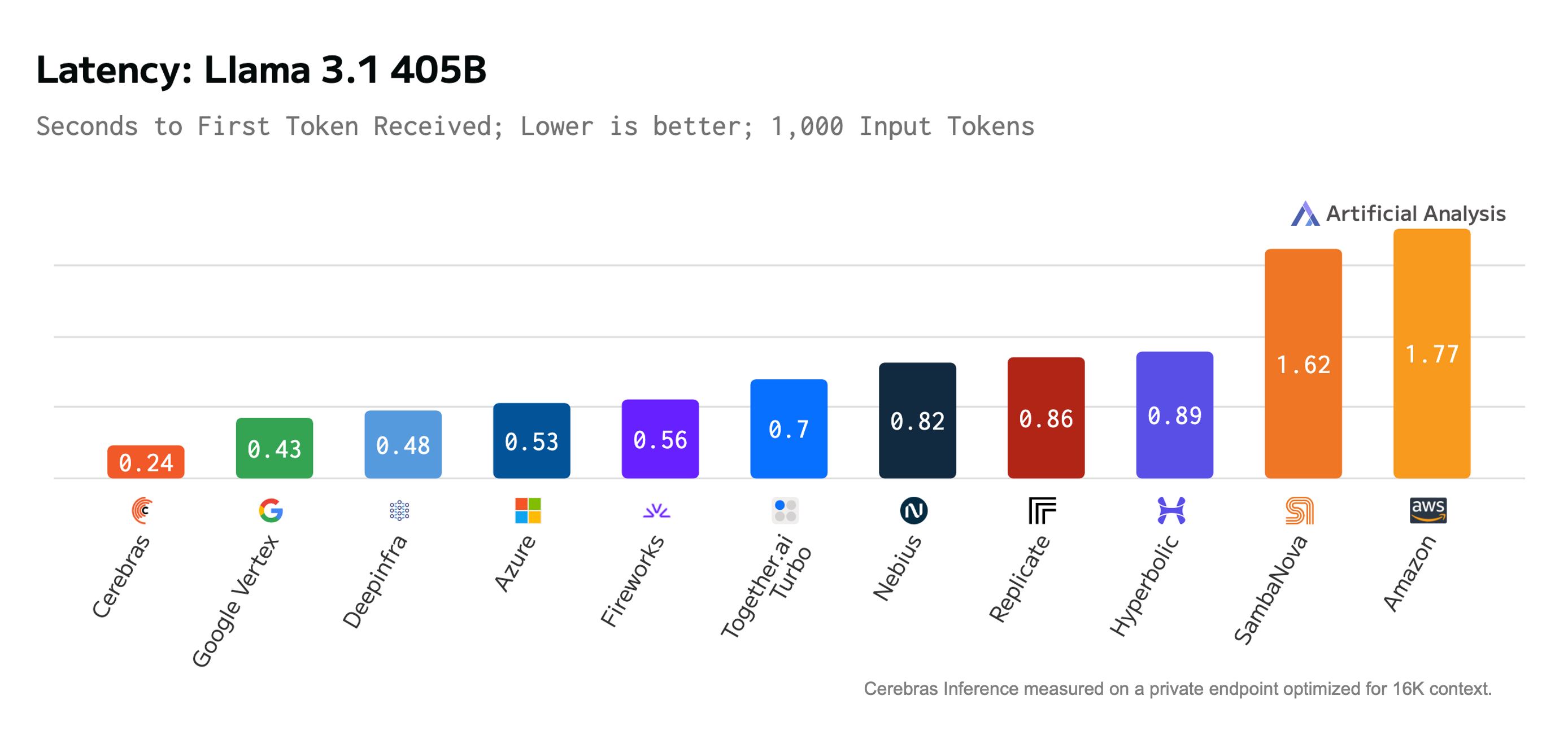
Time-to-first-token is perhaps the most important metric for real-world applications – it’s what users actually experience when interacting with AI. At just 240 milliseconds, Cerebras delivers the fastest time-to-first-token of any platform running Llama 3.1-405B. This is a fraction of what users experience with GPU-based solutions, where initial response times can stretch into seconds. The impact is dramatic: customers switching from GPT-4 to Cerebras Inference report a 75% drop in total latency, dramatically improving the user experience for voice and video AI applications where real-time interaction is crucial.
Availability
Cerebras Inference for Llama 3.1-405B is available in customer trials today, with general availability coming in Q1 2025. Pricing is $6 per million input tokens and $12 per million output tokens. Our output price is 20% lower than AWS, Azure, and GCP.
Open Models Are the Fastest Models
We’re proud to contribute to the Llama ecosystem and the broader open source AI movement. Thanks to the combination of Meta’s open approach and Cerebras’s breakthrough inference technology, Llama 3.1-405B now runs more than 10 times faster than closed frontier models, making it the perfect foundation for voice, video, and reasoning applications where minimal latency and maximum reasoning steps are crucial. Stay tuned for more exciting updates as we push the frontier of instant AI.