Today, we’re excited to announce the launch of DeepSeek R1 Llama-70B on Cerebras Inference. We achieve world record performance over 1,500 tokens/s on this model – 57x faster than GPU solutions. The model runs on Cerebras AI data centers in the US with no data retention, ensuring the best privacy and security for customer workloads. Users can try out the chat application on our website today. We are also offering developer preview via API – please reach out if you’re interested.
DeepSeek R1 is a 671B parameter Mixture of Experts (MoE) model that brings the reasoning capabilities of OpenAI o1 in an open weight model. However, deploying a 671B parameter model presents significant challenges. Reasoning models are also known for their verbosity, often taking 10x longer than traditional models like ChatGPT to generate responses. DeepSeek’s Llama-70B version addresses these challenges by distilling the reasoning capabilities of the larger model into Meta’s widely-supported architecture. This release effectively combines DeepSeek’s advanced reasoning, Llama-70B’s mature ecosystem and deployment efficiency, and Cerebras’s unmatched inference speed – creating one of the most practical and powerful models available today.
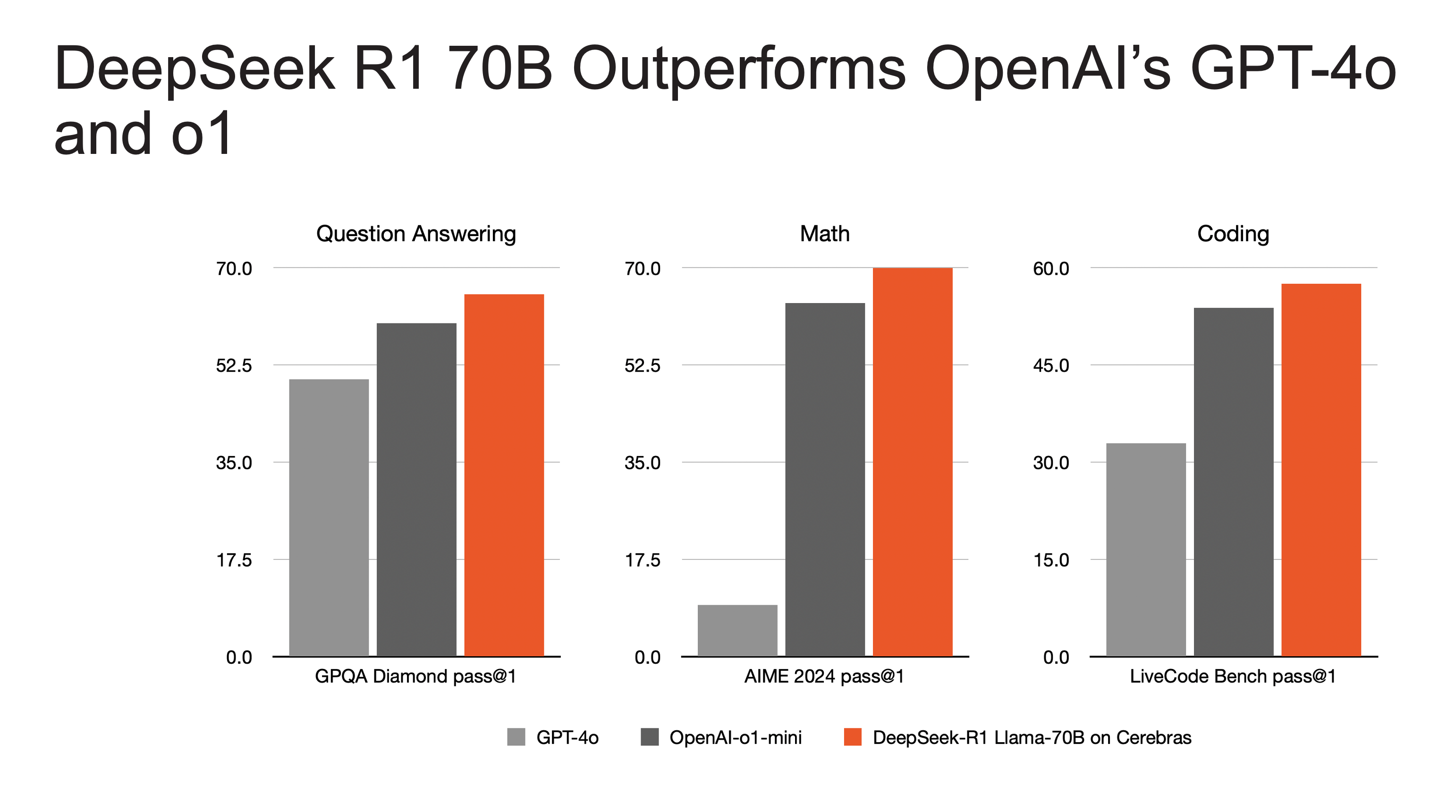
Despite its relatively compact 70B parameter size, DeepSeek R1 Llama-70B outperforms both GPT-4o and o1-mini on challenging mathematics and coding tasks. However, reasoning models like o1 and R1 typically require minutes to compute their answers, compared to seconds for standard language models. This is where fast inference becomes critical.
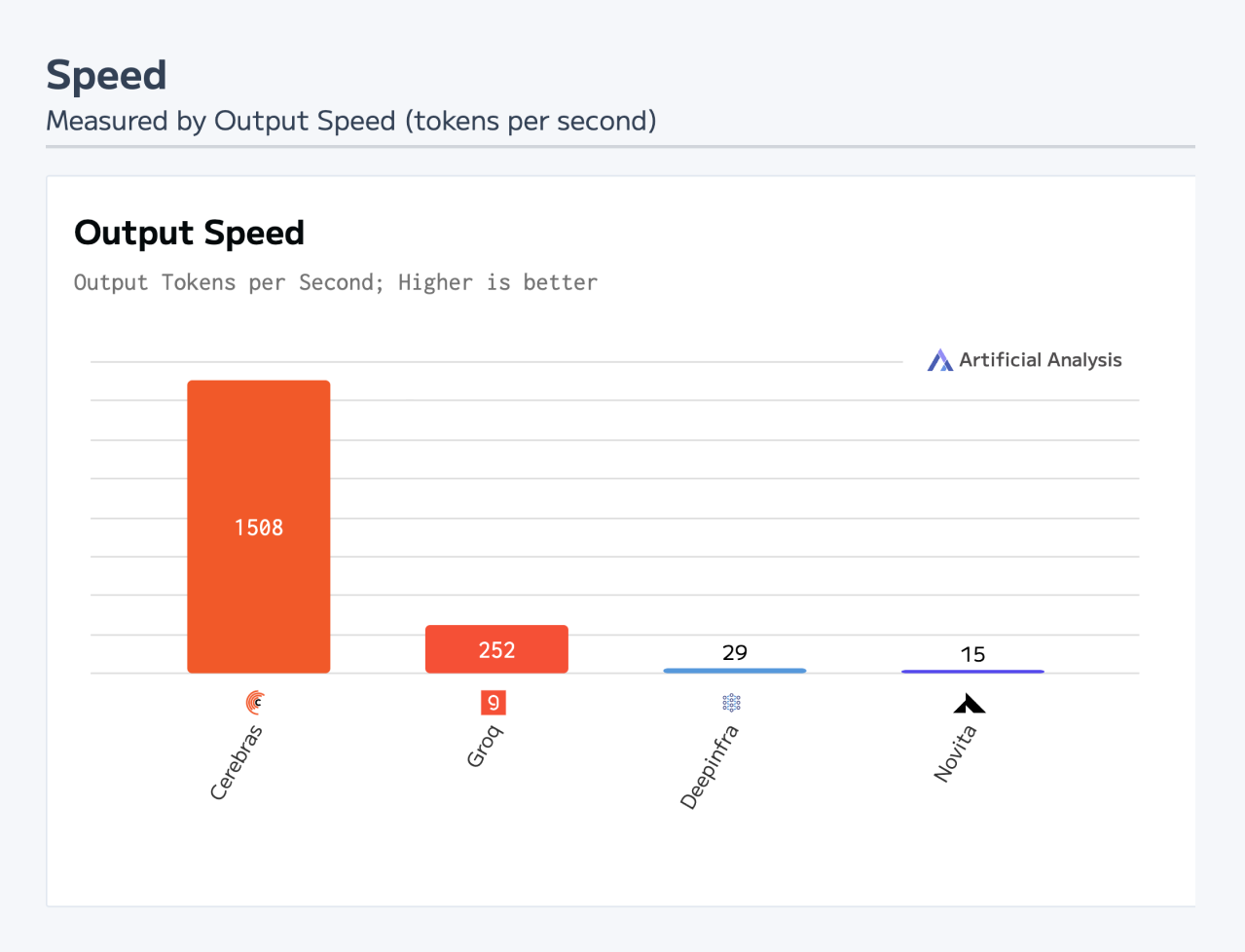
Powered by the Cerebras Wafer Scale Engine, Cerebras Inference is the world’s fastest inference platform. We achieve over 1,500 tokens per second with DeepSeek R1 Llama-70B – 57x faster than GPU solutions. On Cerebras, you don’t have to wait for the model to complete its reasoning chain. The model thinks and provides final answers almost instantaneously.
In our comparison testing, OpenAI’s o1-mini takes 22 seconds to complete a standard coding prompt. The same prompt takes just 1.5 seconds on Cerebras – a 15x improvement in time to result.
Data privacy and security are top priorities for enterprises and developers. Our inference runs 100% on U.S. AI infrastructure. All queries are processed in our own data centers, with zero data retention or transfer. Additionally, DeepSeek R1 Llama-70B can be deployed on-premises in custom data centers, ensuring best-in-class security and data ownership.

Reasoning models represent the next frontier in AI scaling. However, their extended reasoning chains traditionally require minutes of compute time on GPU hardware. Cerebras Inference makes AI fast again – reasoning prompts that take minutes on GPUs complete in seconds on Cerebras, dramatically increasing iteration speed for coding, research, and agent applications.
Cerebras DeepSeek R1 Llama-70B is available today on our website, and we’re offering API preview access to select customers. Contact us to learn more about bringing instant reasoning capabilities to your applications.