The Future of AI is Wafer Scale
Four trillion transistors. 125 petaflops. One silicon wafer. The world’s largest and most powerful processor for AI training and inference.

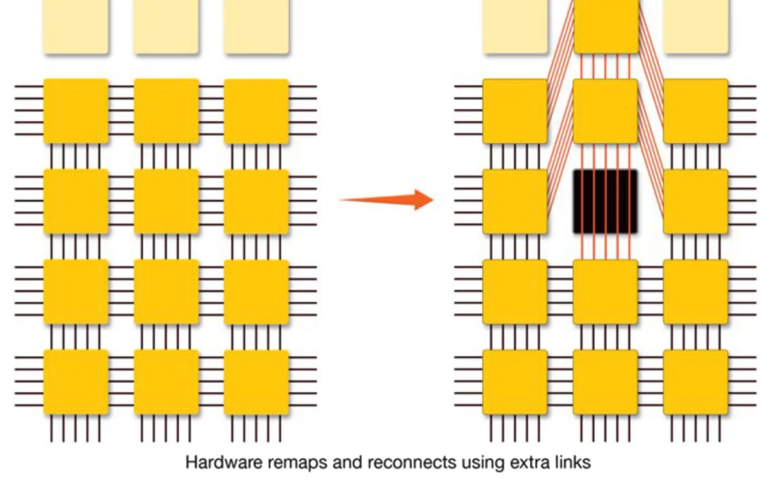
The WSE-3 is the largest AI chip ever built, measuring 46,255 mm² and containing 4 trillion transistors. It delivers 125 petaflops of AI compute through 900,000 AI-optimized cores — 19× more transistors and 28× more compute than the NVIDIA B200.