Apr 09 2025
Llama 4 is now available on Cerebras Inference
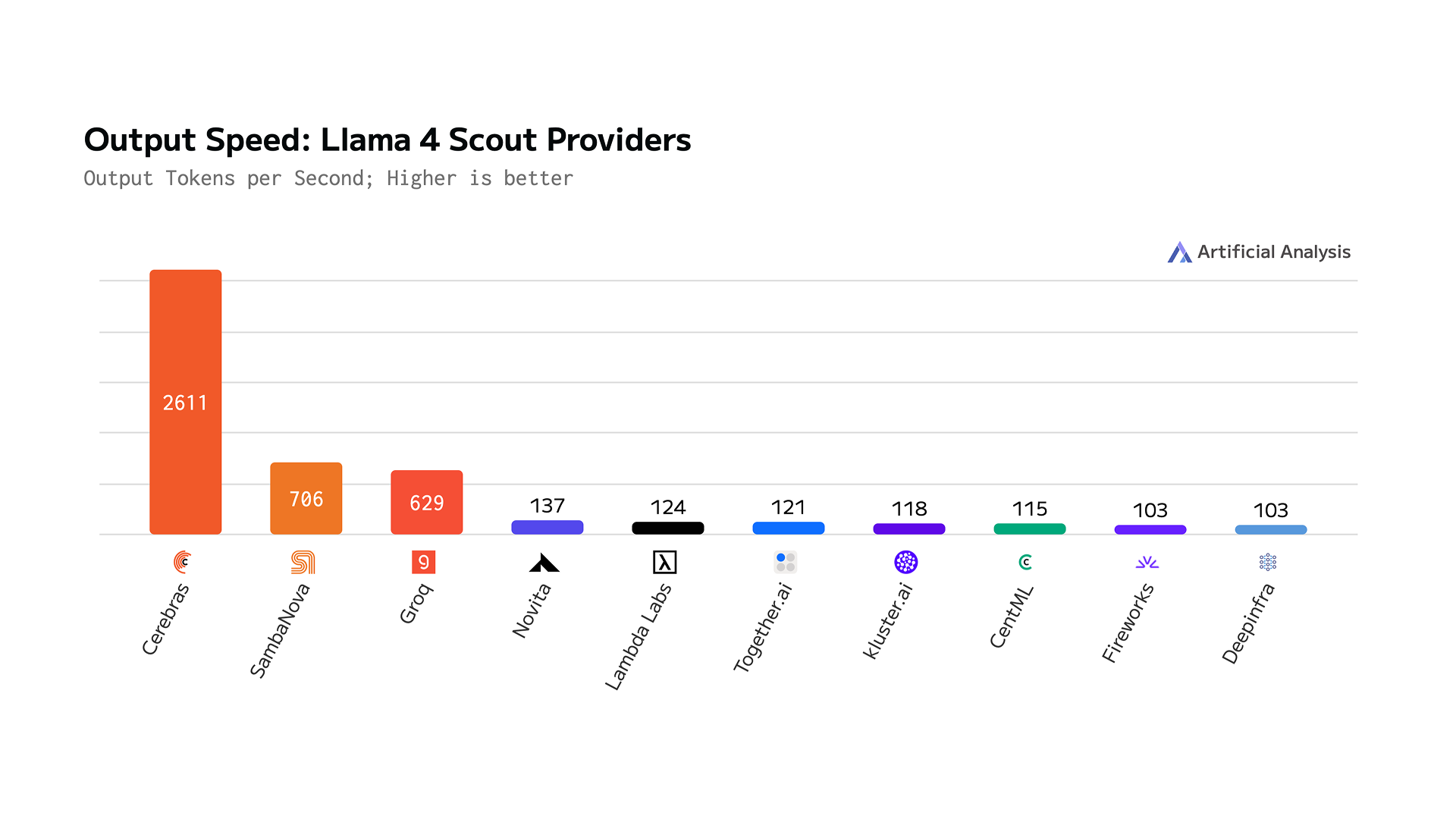
Llama 4 Scout runs at an astounding 2,600 tokens per second– the highest performance ever achieved for any Llama model to date.
Today, we’re excited to announce the launch of Llama 4 on Cerebras. Llama 4 Scout runs at an astounding 2,600 tokens per second – the highest performance ever achieved for any Llama model to date.
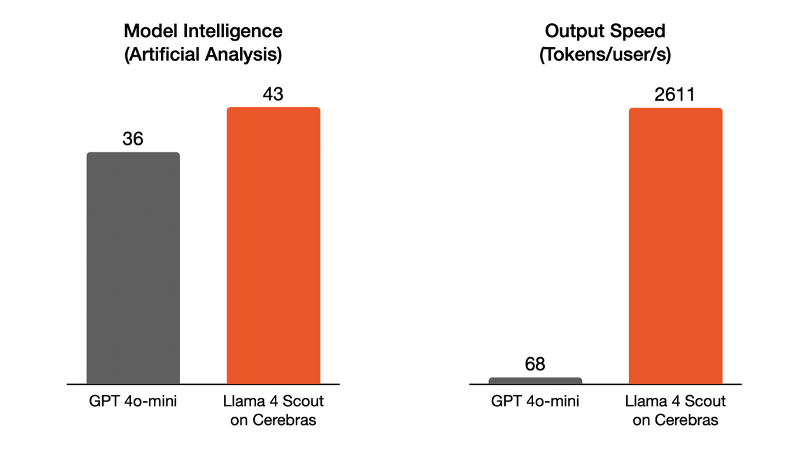
- Llama 4 on Cerebras runs 38x faster than 4o-mini while scoring 19% higher on model evals as measured by Artificial Analysis
- Cerebras is 19x faster than the highest recorded GPU solution in output speed
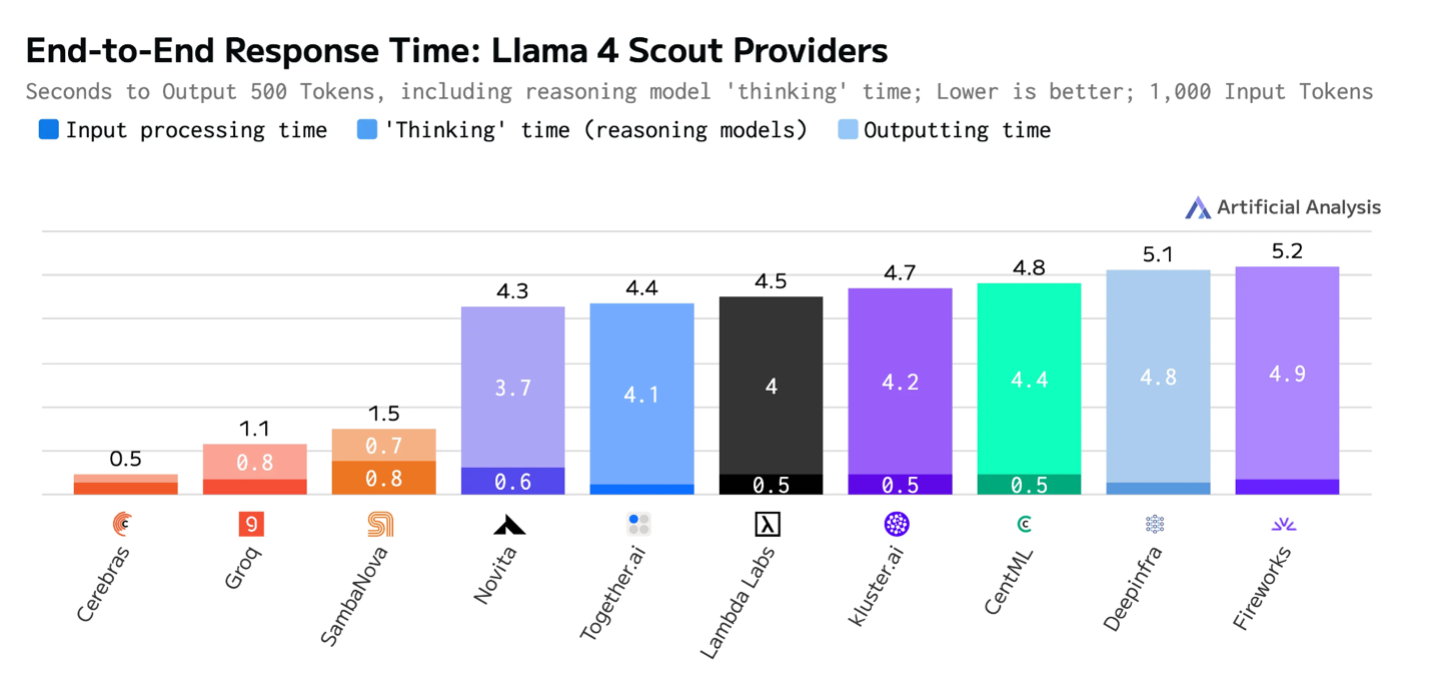
- In total response time (1,000 input tokens and 500 output tokens), Cerebras is the only solution to return the answer in under 1 second – a key enabler of real-time applications.
Llama 4 Scout is available today via chat and on the Cerebras Inference cloud at $0.65 per M input tokens and $0.85 per M output tokens. The larger Llama 4 Maverick model will be available in the near future.
Llama 4 Scout
Llama 4 is the smallest and fastest member of the Llama 4 family of models. With 17B active parameters and 109B total parameters, it is a powerful upgrade over Llama 3.3 70B, offering higher intelligence and lower cost. It is also an ideal endpoint for developers looking to migrate from OpenAI 4o-mini, with a huge step up in model intelligence, 38x faster output speed, and fully open weights.
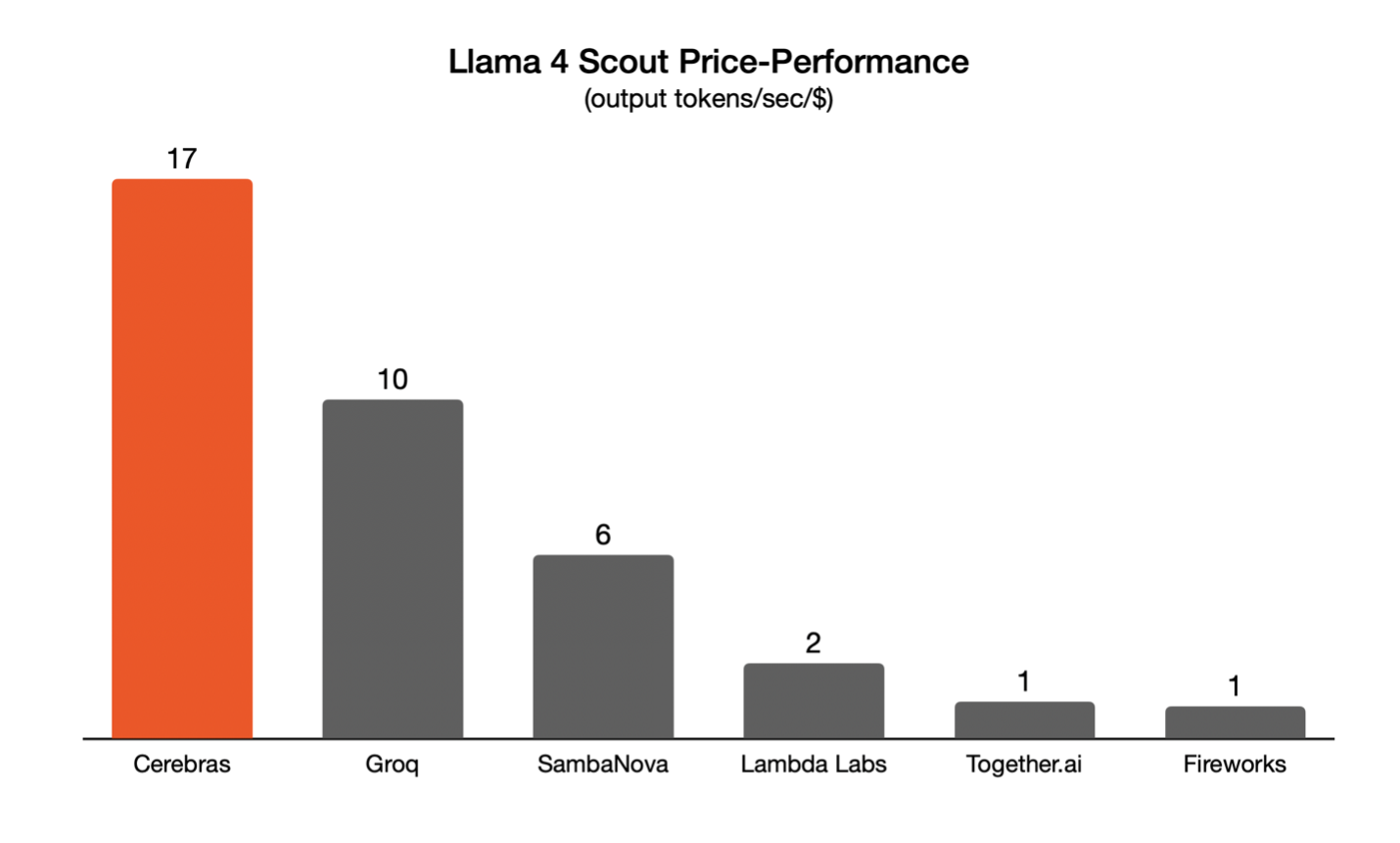
Unmatched Price-Performance
Cerebras leads by a wide margin not just in absolute performance but also price-performance. LLM API pricing is typically expressed in $ per million tokens without regard for speed. But slow tokens and fast tokens have dramatically different use cases and value proposition – a million tokens generated slowly cannot serve real-time applications while a million fast tokens unlocks voice and reasoning applications. To make LLM providers of vastly different speeds comparable relative to cost, we divide output speed with $ per million tokens. Cerebras provides 17x better price-performance relative to leading GPU solutions and 70% superior to the next best offering — wafer-scale is not only incredibly fast, it provides the best price-performance of any hardware platform.
Availability
Try Llama 4 Scout today on the Cerebras chat app. Developers can get API access through the Cerebras Inference cloud or HuggingFace. Llama 4 Maverick will be released in the near future.