Today, we are announcing Cerebras inference – the fastest AI inference solution in the world. Cerebras inference delivers 1,800 tokens per second for Llama3.1 8B and 450 tokens per second for Llama3.1 70B, which is 20x faster than NVIDIA GPU-based hyperscale clouds. Cerebras inference is open to developers today via API access with generous rate limits.
Powered by the third generation Wafer Scale Engine, Cerebras inference runs Llama3.1 20x faster than GPU solutions at 1/3 the power of DGX solutions. At 1,800 tokens/s, Cerebras Inference is 2.4x faster than Groq in Llama3.1-8B. For Llama3.1-70B, Cerebras is the only platform to enable instant responses at a blistering 450 tokens/sec. All this is achieved using native 16-bit weights for the model, ensuring the highest accuracy responses.
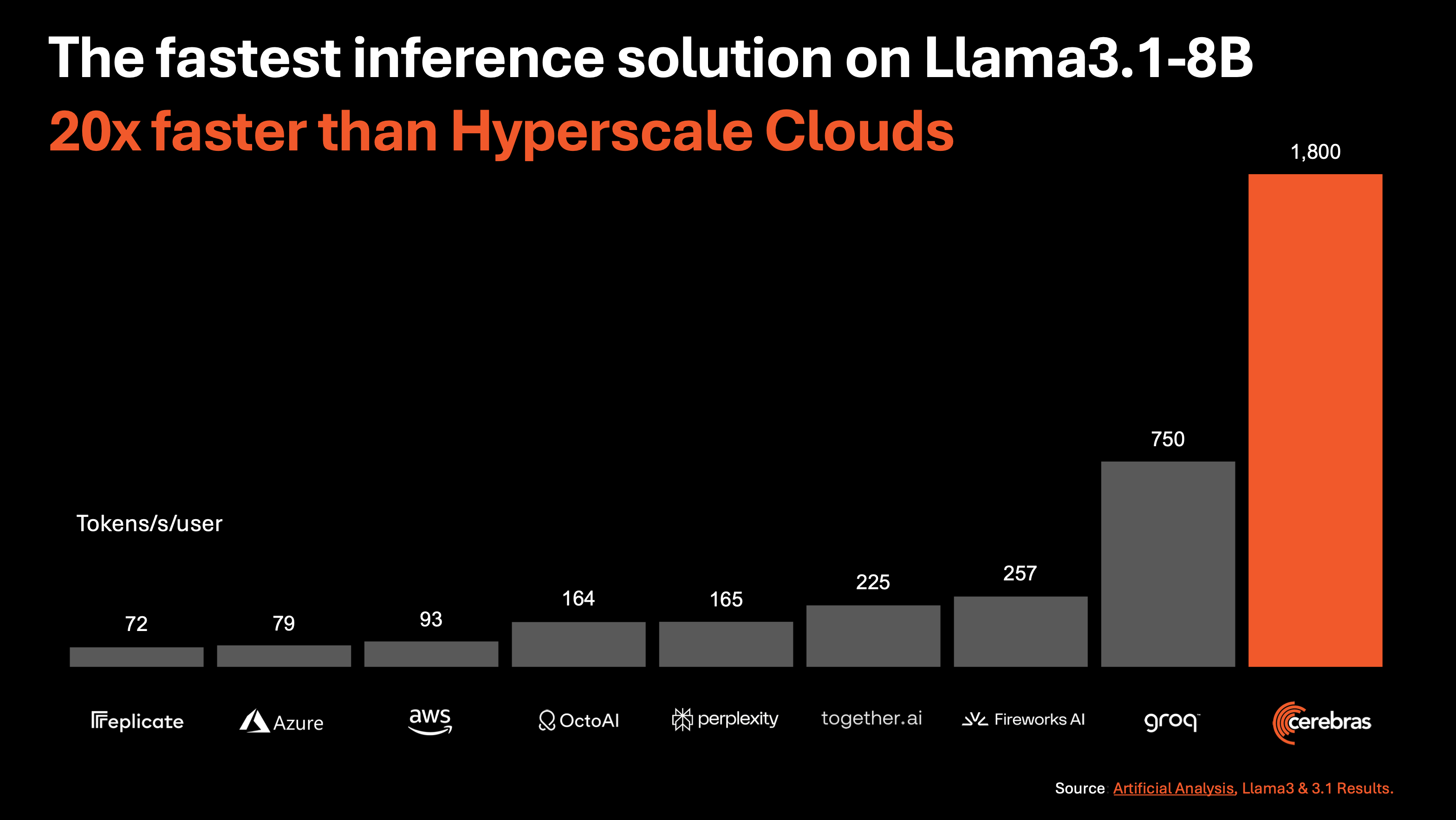
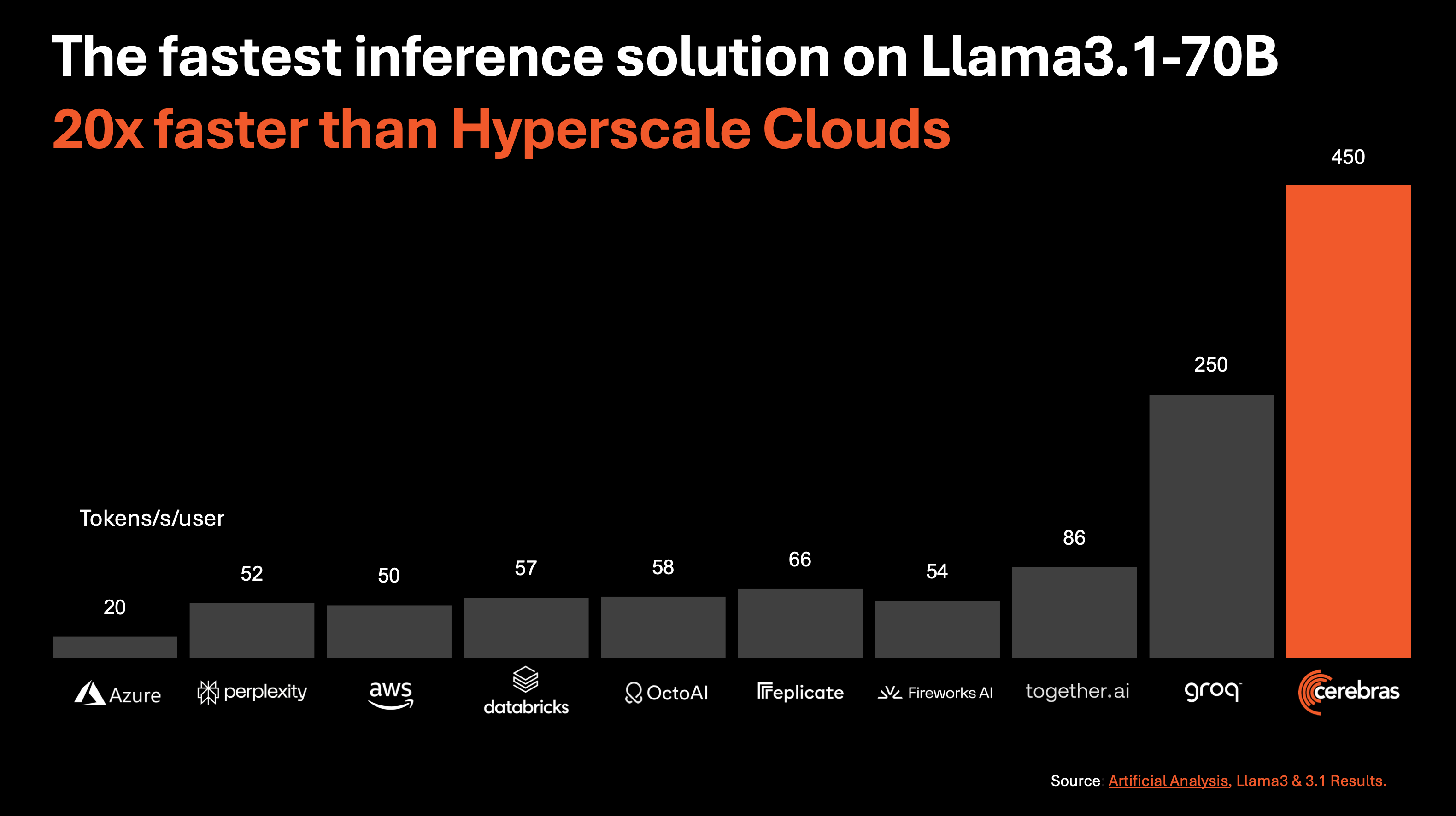
Why GPU inference feels slow
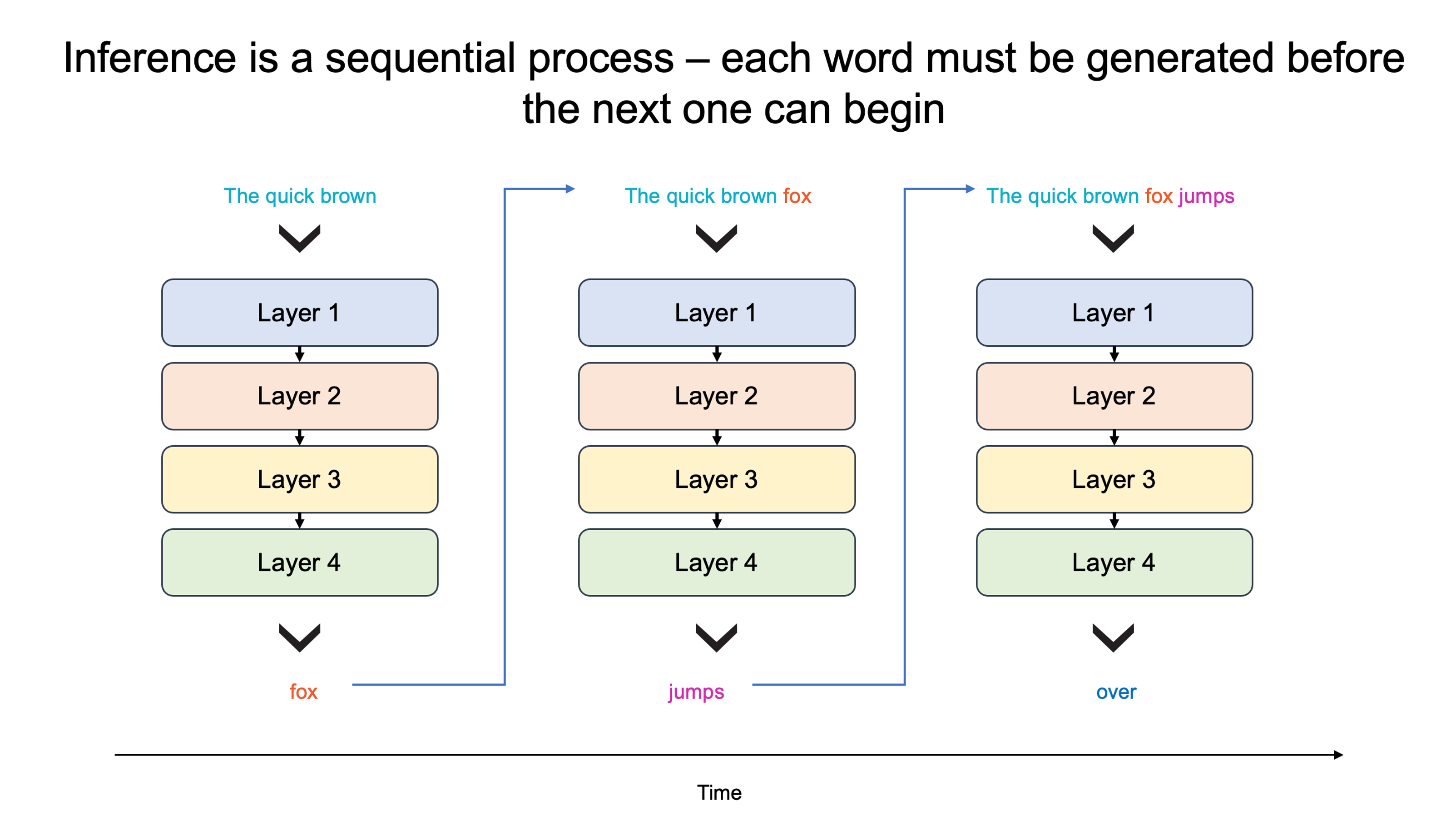
Why do responses from large language models (LLMs) trickle in one word at a time, reminiscent of loading webpages on dialup internet? The reason lies in the sequential nature of LLMs and the vast amounts of memory and bandwidth they require. In LLMs, each word generated must be processed through the entire model—all its parameters must be moved from memory to computation. Generating one word takes one pass, generating 100 words requires 100 passes – since each word is dependent on the prior word, this process cannot be run in parallel. Thus to generate a 100 words a second requires moving the model 100 times per second – requiring vast amounts of memory bandwidth.
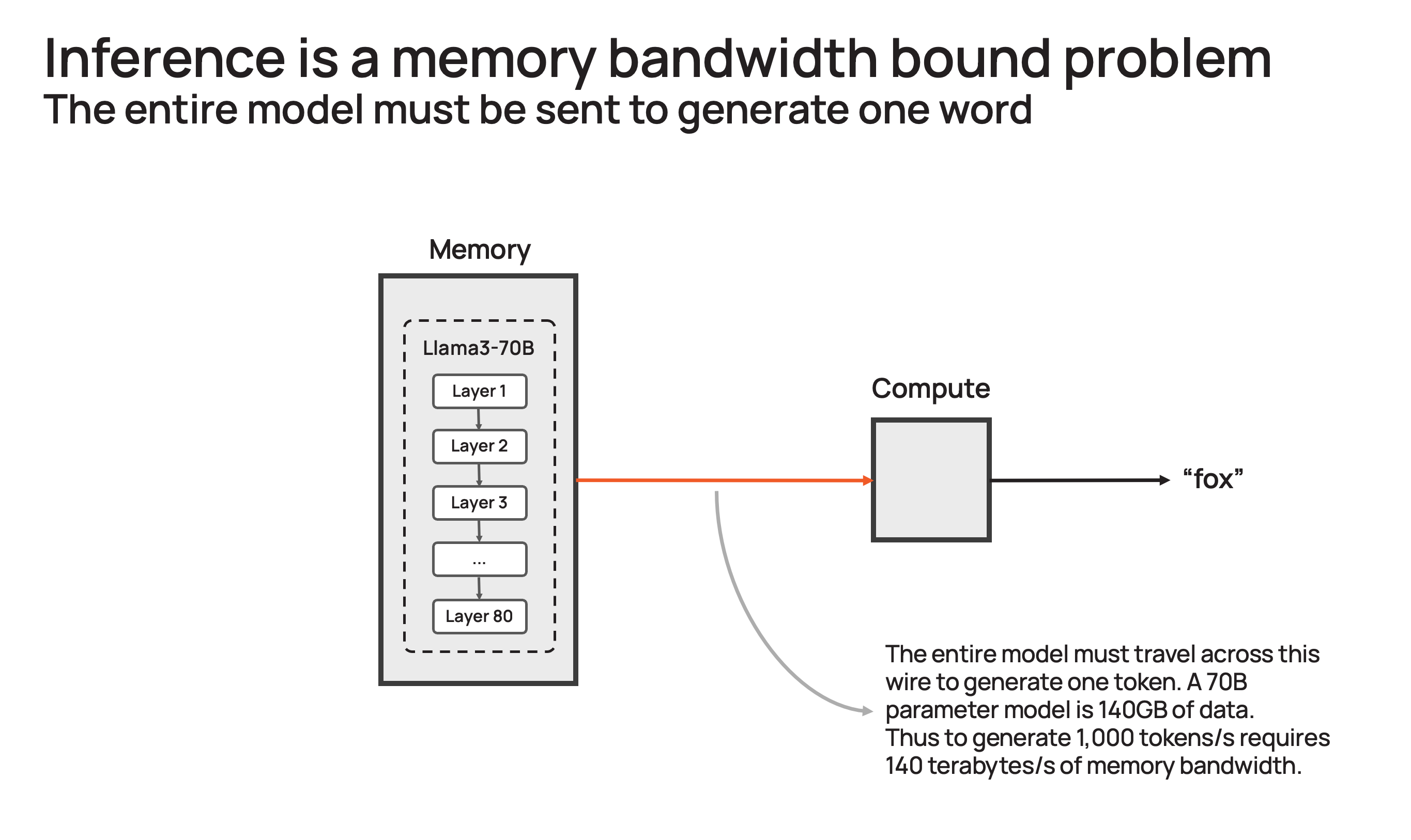
Take the popular Llama3.1-70B model. The model has 70 billion parameters. Each parameter is 16-bit, requiring 2 bytes of storage. The entire model requires 140GB of memory. For the model to output one token, every parameter must be sent from memory to the compute cores to perform the forward pass inference calculation. Since GPUs only have ~200MB of on-chip memory, the model cannot be stored on-chip and must be sent in its entirety to generate every output token.
Generating one token requires moving 140GB once from memory to compute. To generate 10 tokens per second would require 10 * 140 = 1.4 TB/s of memory bandwidth. A H100 has 3.3 TB/s of memory bandwidth – sufficient for this slow inference. Instantaneous inference would require ~1,000 tokens per second or 140 TB/s – far exceeding the memory bandwidth of any GPU server or system. Moreover, this cannot be solved by simply chaining more DGX systems together – adding more processors increases the throughput of the system (i.e., more queries) but does not speed up the response time of individual queries.
How Cerebras lifts the memory bandwidth barrier
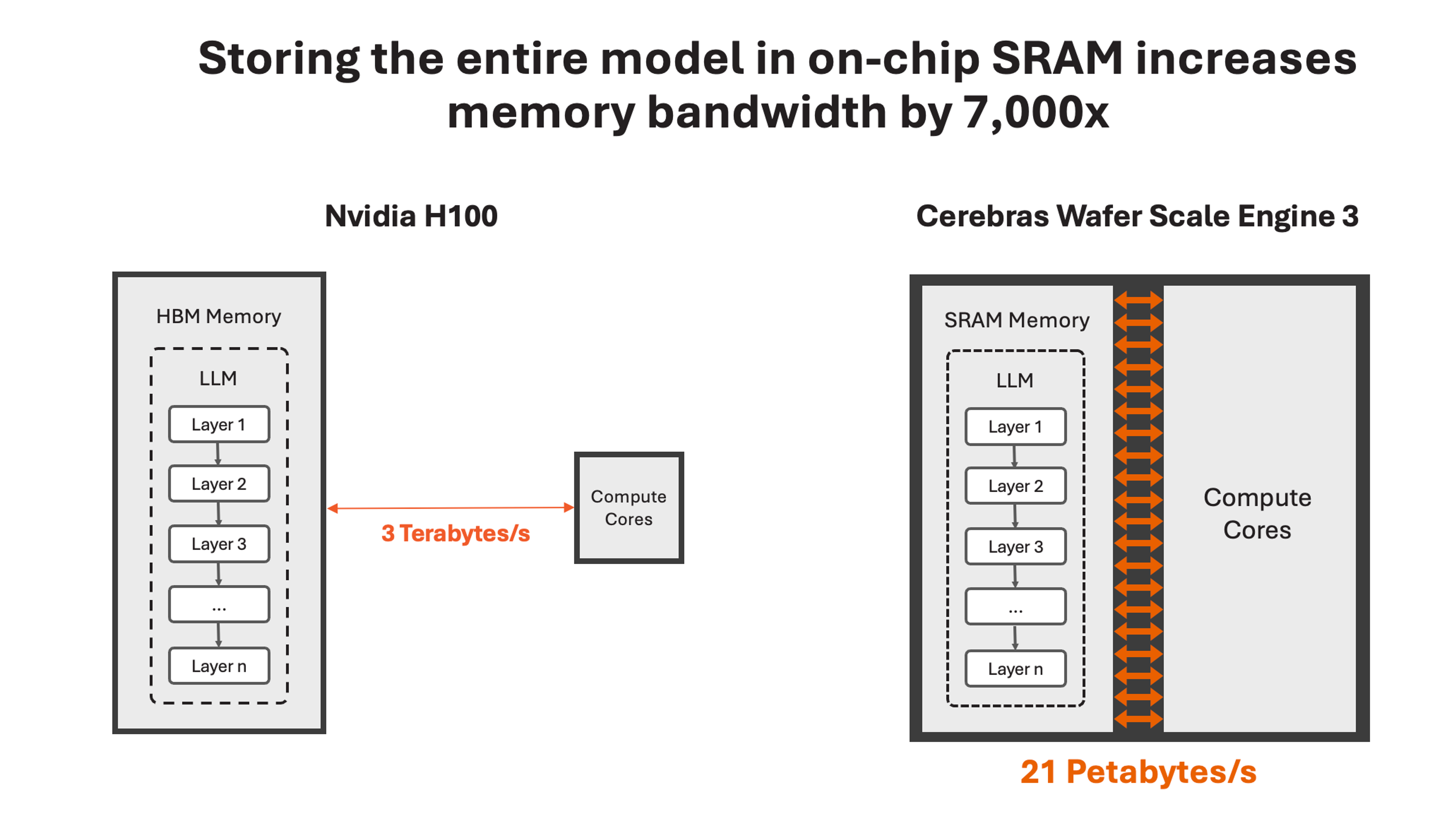
Cerebras solves the memory bandwidth bottleneck by building the largest chip in the world and storing the entire model on-chip. With our unique wafer-scale design, we are able to integrate 44GB of SRAM on a single chip – eliminating the need for external memory and for the slow lanes linking external memory to compute.
In total, the WSE-3 has 21 petabytes/s of aggregate memory bandwidth – 7,000x that of an H100. It is the only AI chip with both petabyte-scale compute and petabyte-scale memory bandwidth, making it a near ideal design for high-speed inference.
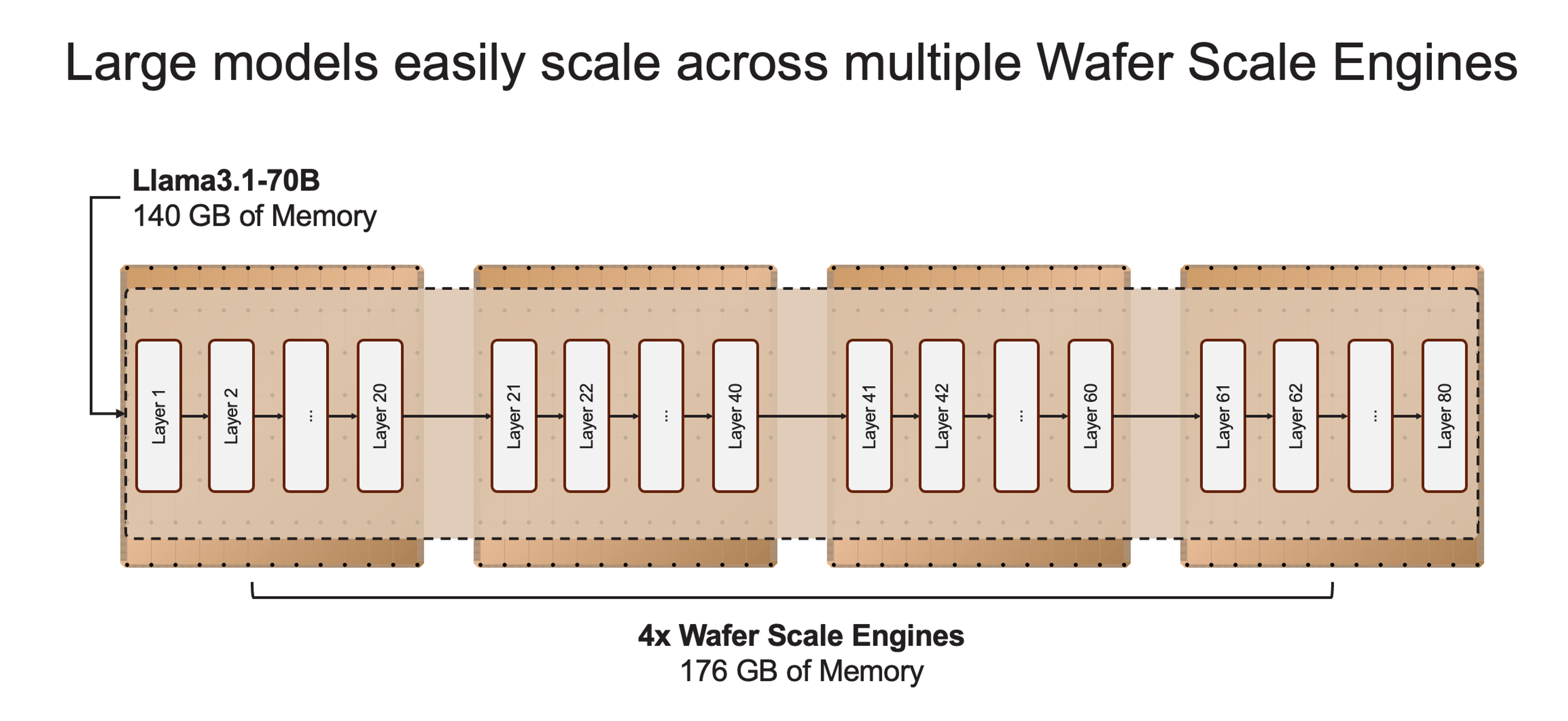
Cerebras inference is designed to serve models from billions to trillions of parameters. When models exceed the memory capacity of a single wafer, we split them at layer boundaries and map them to multiple CS-3 systems. 20B models fit on a single CS-3 while 70B models fit on as few as four systems. In the weeks to come we will be adding larger models such as Llama3-405B and Mistral Large with industry leading speed and cost per token.
16-bit model weights for the highest accuracy
Some companies try to overcome the memory bandwidth bottleneck by reducing weight precision from 16-bit to 8-bit, often without informing their users. This approach, however, can result in loss of accuracy. Cerebras inference runs Llama3.1 8B and 70B models using the original 16-bit weights released by Meta, ensuring the most accurate and reliable model output. Our evaluations, along with third-party benchmarks, show that 16-bit models score up to 5% higher than their 8-bit counterparts, resulting in substantially better performance in multi-turn conversations, math, and reasoning tasks.
Cerebras Inference API

Cerebras inference is available today via chat and API access. Built on the familiar OpenAI Chat Completions format, it allows developers to integrate our powerful inference capabilities by simply swapping out the API key.
Cerebras inference API offers the best combination of performance, speed, accuracy and cost. At 450 tokens per second, it’s the only solution that runs Llama3.1-70B at instantaneous speed. We use Meta’s original 16-bit model weights, ensuring the highest accuracy. For launch we are providing developers with 1 million free tokens daily. For at scale deployments, our pricing is a fraction of popular GPU clouds.
For initial launch, we are offering Llama3.1 8B and 70B models. We will be adding support for larger models such as Llama3 405B and Mistral Large 2 in the coming weeks. Please let us know what models you’d like to see added.
Why fast inference matters
The implications of high-speed inference extend far beyond raw metrics. By dramatically reducing processing time, we’re enabling more complex AI workflows and enhancing real-time LLM intelligence. Traditional LLMs output everything they think immediately, without stopping to consider the best possible answer. New techniques like scaffolding, on the other hand, function like a thoughtful agent who explores different possible solutions before deciding. This “thinking before speaking” approach provides over 10x performance on demanding tasks like code generation, fundamentally boosting the intelligence of AI models without additional training. But these techniques require up to 100x more tokens at runtime, and thus is only possible in real time running on Cerebras hardware.
With record-breaking performance, industry-leading pricing, and open API access, Cerebras Inference sets a new standard for open LLM development and deployment. As the only solution capable of delivering both high-speed training and inference, Cerebras opens entirely new capabilities for AI. We can’t wait to see the new and exciting applications developers will build with Cerebras Inference.
Links: