Oct 24 2024
Cerebras Inference now 3x faster: Llama3.1-70B breaks 2,100 tokens/s - Cerebras
Today we’re announcing the biggest update to Cerebras Inference since launch. Cerebras Inference now runs Llama 3.1-70B at an astounding 2,100 tokens per second – a 3x performance boost over the prior release. For context, this performance is:
- 16x faster than the fastest GPU solution
- 8x faster than GPUs running Llama3.1-3B, a model 23x smaller
- Equivalent to a new GPU generation’s performance upgrade (H100/A100) in a single software release
Fast inference is the key to unlocking the next generation of AI apps. From voice, video, to advanced reasoning, fast inference makes it possible to build responsive, intelligent applications that were previously out of reach. From Tavus revolutionizing video generation to GSK accelerating drug discovery workflows, leading companies are already using Cerebras Inference to push the boundaries of what’s possible. Try Cerebras Inference using chat or API at inference.cerebras.ai.
Benchmarks
Cerebras Inference has been rigorously tested by Artificial Analysis, a third-party benchmarking organization. We reproduce their performance charts below.
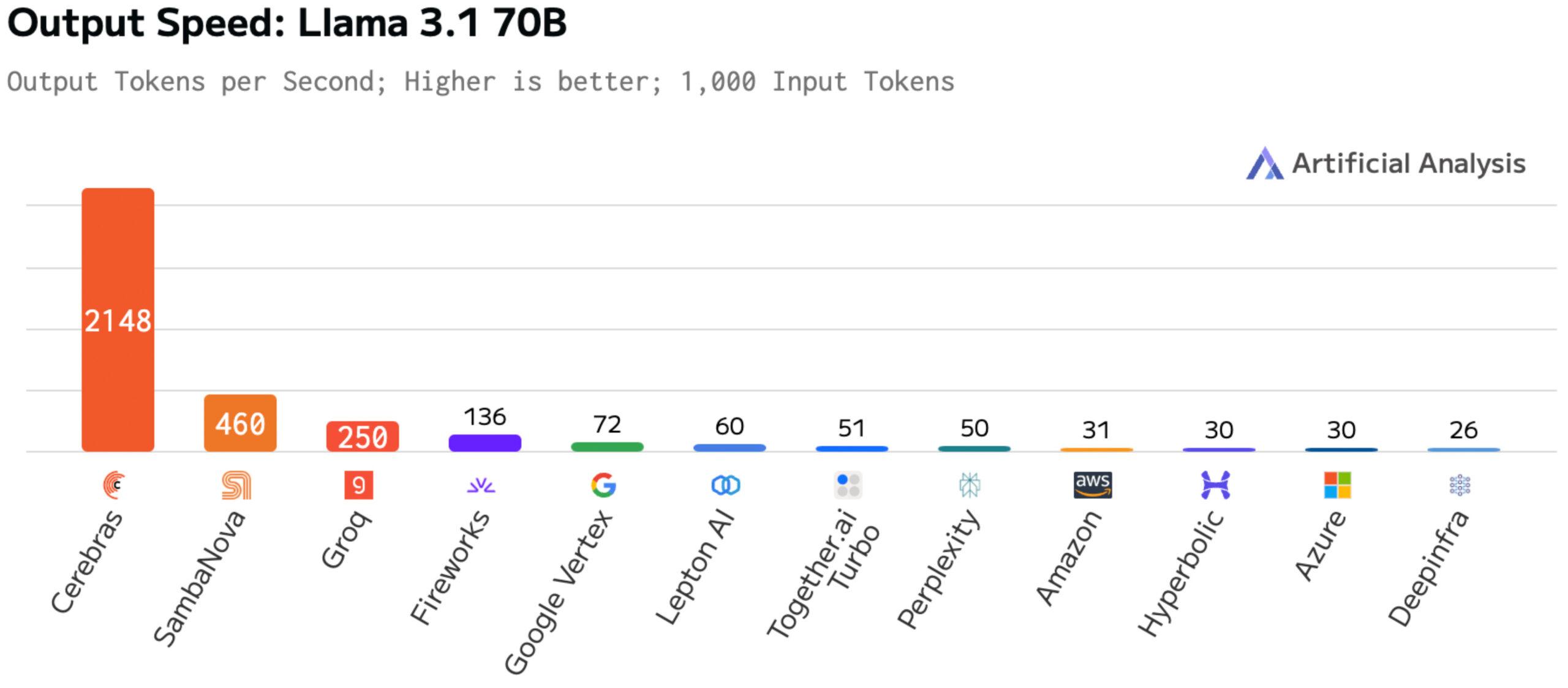
In output speed per user, Cerebras Inference is in a league of its own – 16x faster than the most optimized GPU solution, 68x faster than hyperscale clouds, and 4-8x faster than other AI accelerators.
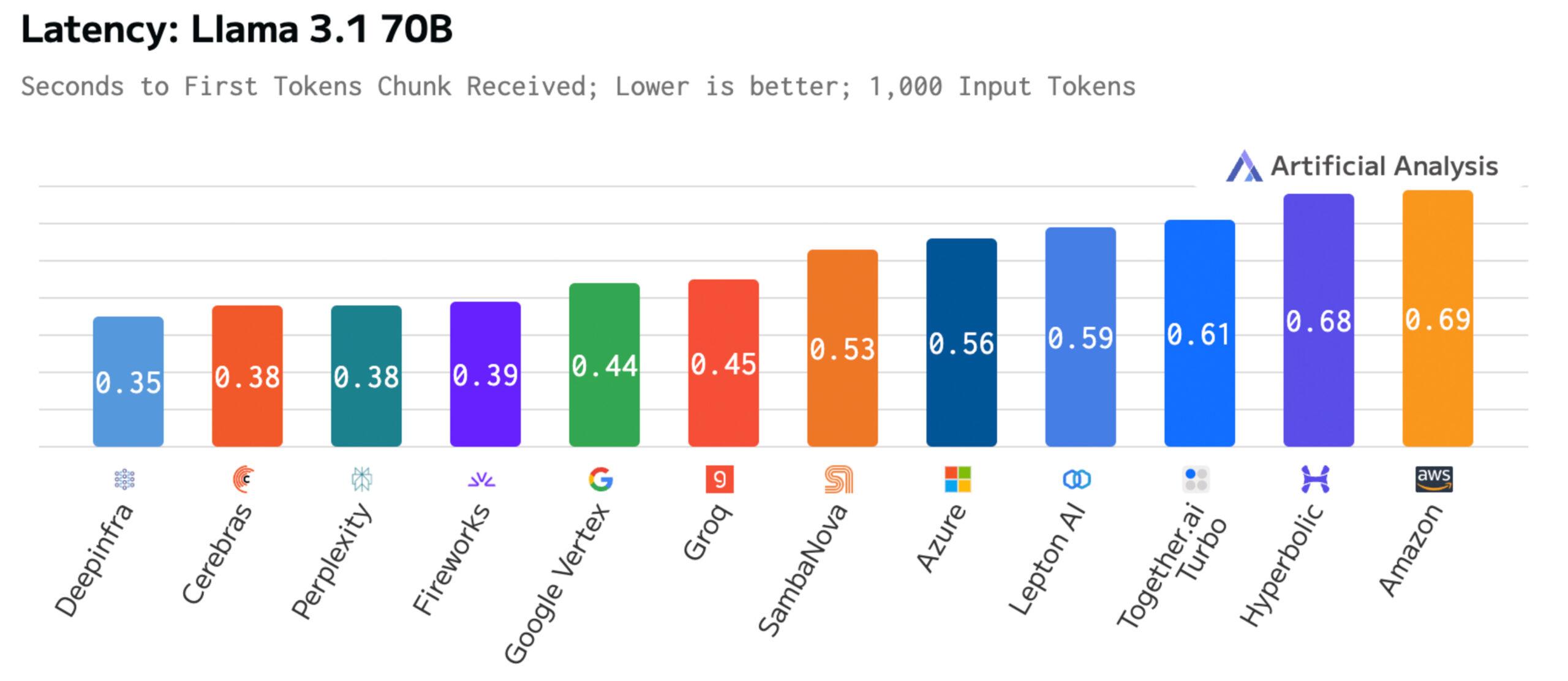
Time to first token is critical for real time applications. Cerebras is tied second place in first token latency, showing the advantage of a wafer-scale integrated solution vs. complex networked solutions.
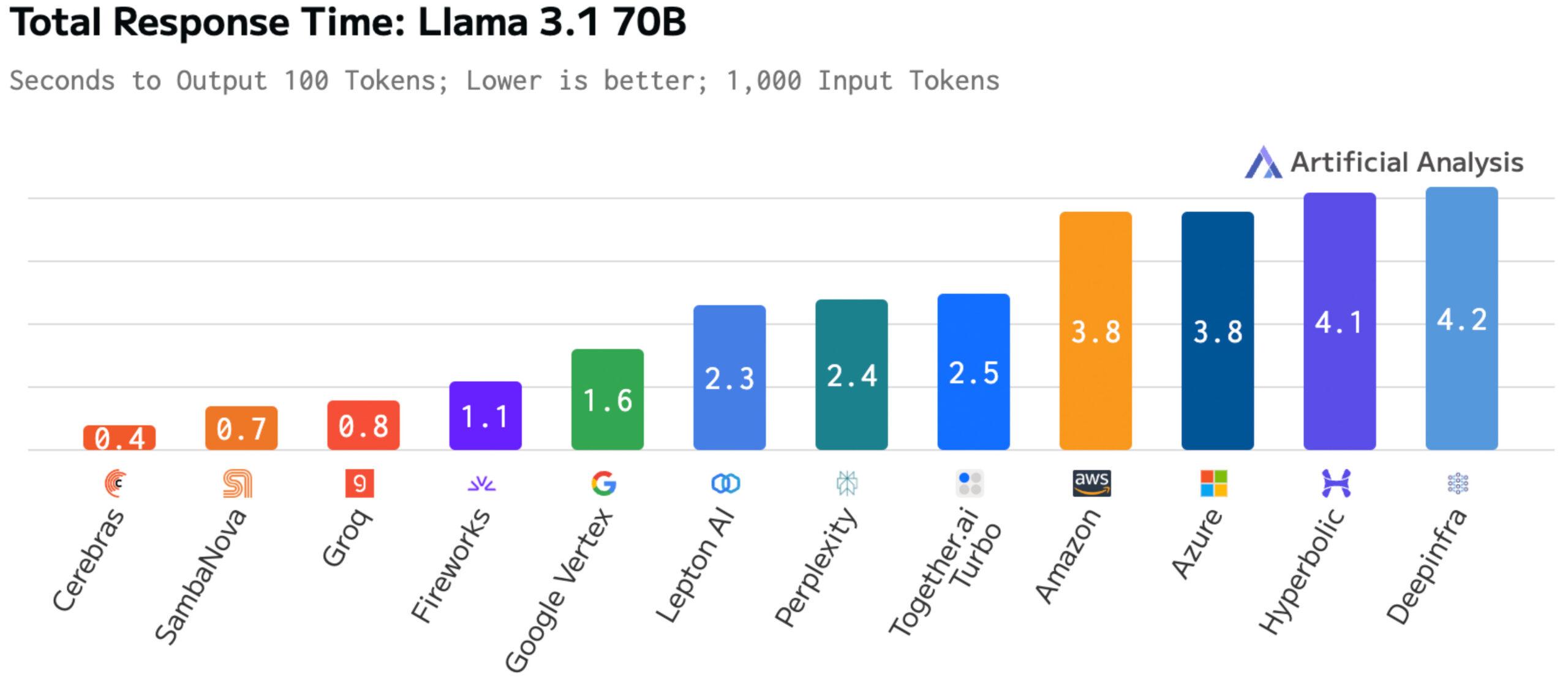
Total response time – measuring a full turn of input and output – is a good proxy for multi-step agentic workflows. Here Cerebras Inference completes a full request in just 0.4 of a second vs. 1.1 to 4.2 seconds on GPU based solutions. For agents, this means getting up to 10x more work done in the same time. For reasoning models, this enables 10x more reasoning steps without increasing response time.
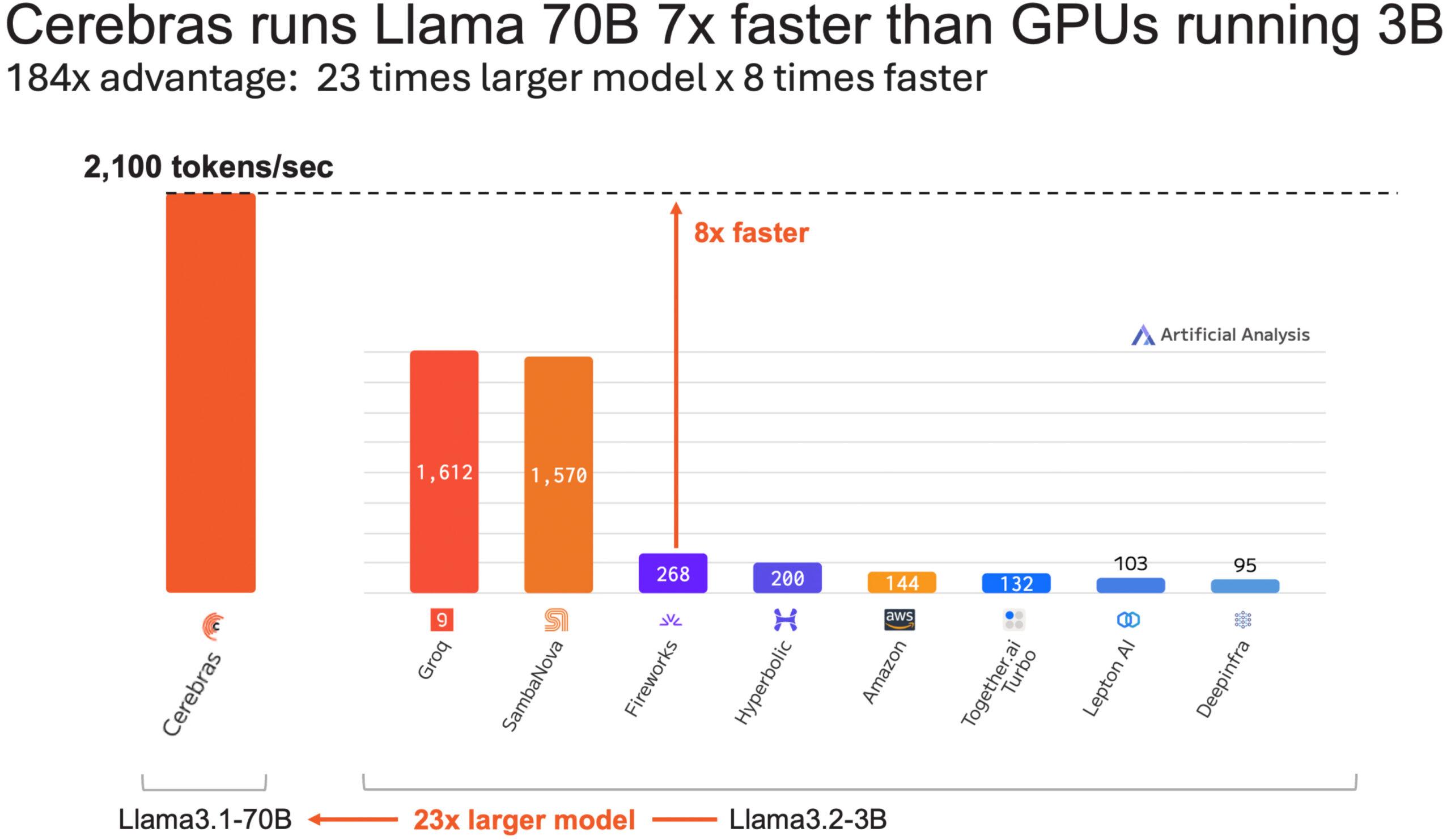
Cerebras Inference running Llama3.1 70B is now so fast that it outruns GPU based inference running Llama3.1 3B. The Wafer Scale Engine runs an AI model 23x larger at 8x speed for a combined 184x performance advantage.
Optimized kernels, stack, and ML
The first release of Cerebras Inference in August set new speed records and made Llama3.1-70B an instantaneous experience. While it was incredibly fast, it was the first implementation of inference on the Wafer Scale Engine and utilized only a fraction of its peak bandwidth, compute, and IO capacity. Today’s release is the culmination of numerous software, hardware, and ML improvements we made to our stack to greatly improve the utilization and real-world performance of Cerebras Inference.
We’ve re-written or optimized the most critical kernels such as MatMul, reduce/broadcast, element wise ops, and activations. Wafer IO has been streamlined to run asynchronously from compute. This release also implements speculative decoding, a widely used technique that uses a small model and large model in tandem to generate answers faster. As a result of this feature, you may observe a greater variance in output speed – 20% higher or lower than the 2,100 tokens/sec average is normal.
Model precision is unchanged – all models continue to use 16-bit original weights. Model output accuracy is likewise unchanged as verified by Artificial Analysis.
What fast inference enables
The impact of Cerebras Inference’s unprecedented speed is already transforming how organizations develop and deploy AI apps. In pharmaceutical research, Kim Branson, SVP of AI and ML at GSK, says: “With Cerebras’ inference speed, GSK is developing innovative AI applications, such as intelligent research agents, that will fundamentally improve the productivity of our researchers and drug discovery process.”
The dramatic speed improvement is game-changing for real-time AI applications, as demonstrated by LiveKit, which powers ChatGPT’s voice mode. As CEO Russ d’Sa explains: “When building voice AI, inference is the slowest stage in your pipeline. With Cerebras Inference, it’s now the fastest. A full pass through a pipeline consisting of cloud-based speech-to-text, 70B-parameter inference using Cerebras Inference, and text-to-speech, runs faster than just inference alone on other providers. This is a game changer for developers building voice AI that can respond with human-level speed and accuracy.”
Fast inference is the key enabler for next gen AI applications that leverage more test-time compute for greater model capability. As demonstrated by models like GPT-o1, the ability to perform extensive chain-of-thought reasoning directly translates to breakthrough performance in reasoning, coding, and research tasks. Using Cerebras Inference, models think deeply before responding without the typical minutes-long latency penalties. This makes Cerebras Inference the ideal platform for developers looking to build systems that deliver both greater runtime intelligence and responsive user experiences.
Conclusion
Today’s 3x performance improvement shows what’s possible when realizing the full potential of the Wafer Scale Engine for inference. At 2,100 tokens per second for Llama3.1-70B, we’ve delivered the equivalent of more than a hardware generation’s worth of performance in a single software release. Our team continues to optimize both software and hardware capabilities, and we will be expanding our model selection, context lengths, and API features in the coming weeks.