
AI for finance services
AI has transformative potential to improve financial forecasting, fraud detection, and customer service.
customer use case
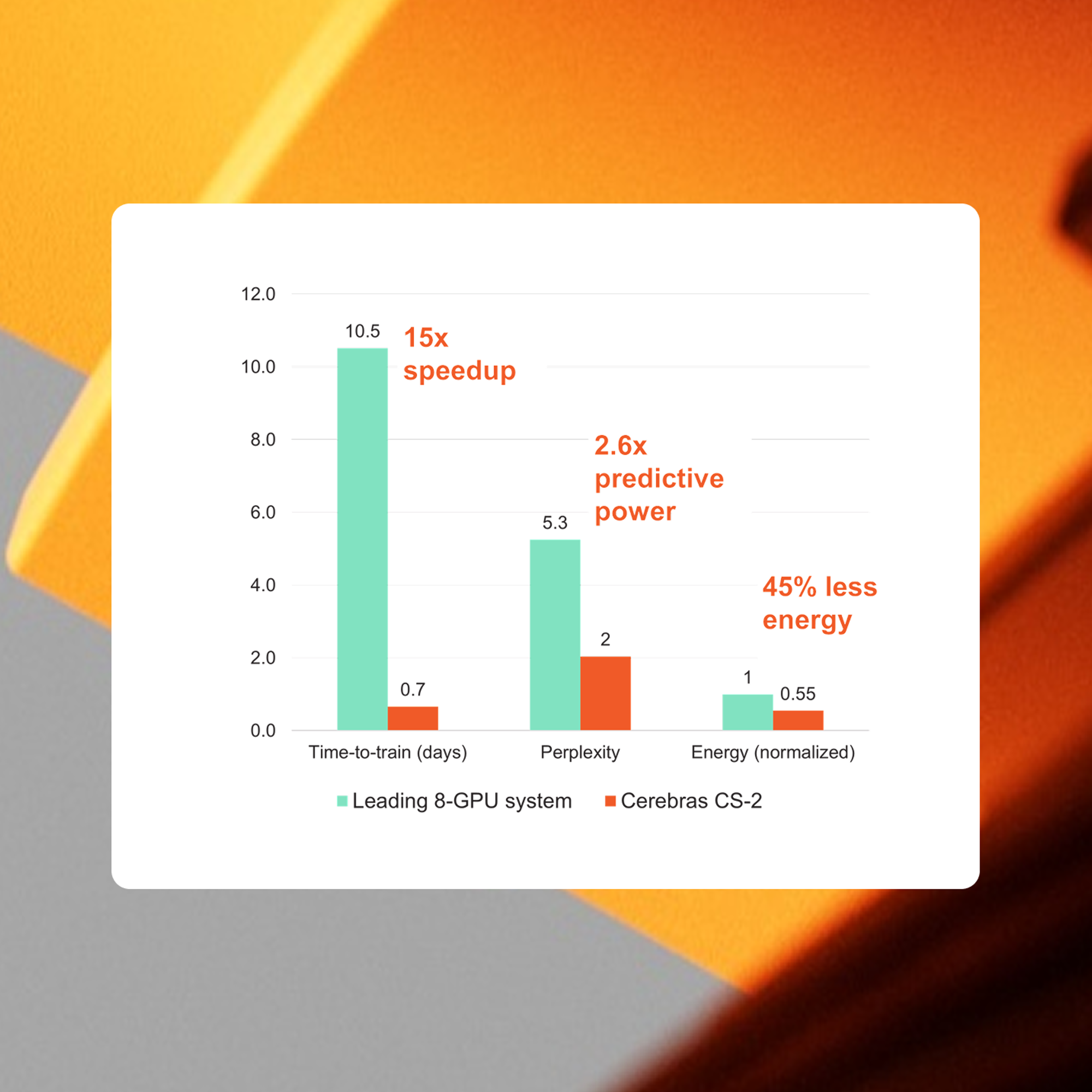
Accelerating NLP Model Training and Enabling Higher Accuracy for Financial Services Applications
A project conducted by a leading financial services institution and Cerebras Systems demonstrated that training from scratch using domain-specific datasets for Financial Services applications could be made practical in an enterprise environment for the first time.

use case
Text and document analysis
State of the art natural language models have the potential to put deep insights from massive news, literature, or records databases at analysts fingertips in an instant. However, these models often take days, weeks, or even months to train on legacy GPU clusters that require parallel programming. With the CS-3 system, enterprise researchers and analysts can develop models and get answers back orders of magnitude faster to deliver AI insights ahead of the market.
use case
Fraud detection
Fraud is costly and increasingly challenging to detect, making its detection and management one of the most attractive AI for financeial services. Fortunately, massive volumes of transaction data and AI models can be combined to alert customers’ and analysts’ attention to suspicious activity before damage is done. Cerebras’ revolutionary WSE deep learning processor makes training and running state of the art language, time series, and graph models in production happen orders of magnitude faster than legacy computer systems with the programming ease of a single desktop machine.


use case
Algorithmic trading and management
Data and AI are changing the way we engage with the market and manage our portfolios, but handling large datasets at low latency is a must. The WSE’s massive compute combined with supercomputer-impossible memory and communication bandwidth enable orders of magnitude higher data throughput and lower computation time than legacy distributed processor architectures for this work.