Feb 11 2025
Visualizing Knowledge at Lightning Speed with Cerebras at Tako - Cerebras
Today’s internet is a vast sea of information, but finding reliable, well-presented data can feel like searching for a needle in a haystack. Apps that rely exclusively on LLMs and the open web hallucinate, are out of date, and miss out on the most important authoritative data that’s not readily crawlable.
Tako is changing this landscape with its innovative search engine that collects data and presents it in interactive charts and graphs called “knowledge cards.” Unlike traditional search engines that simply crawl and index the open web, Tako curates information from authoritative sources, ensuring accuracy and reliability. Developers use Tako to build rich, interactive and visual AI-native products.
The dream: processing data on-the-fly for live visual suggestions
Tako leverages large language models (LLMs) in their Natural Language Processing (NLP) pipeline to take a user’s question and translate it to their proprietary structured query format. Most of Tako’s customers use their platform to serve consumer search and productivity use cases, where latency is measured in mere milliseconds.

Tako’s Related Search feature aims to enhance AI content creation by providing relevant knowledge cards based on the user’s input. For example, if a user is writing an essay comparing Ford and Tesla’s financial performance, Tako would automatically generate stock price charts for both companies.
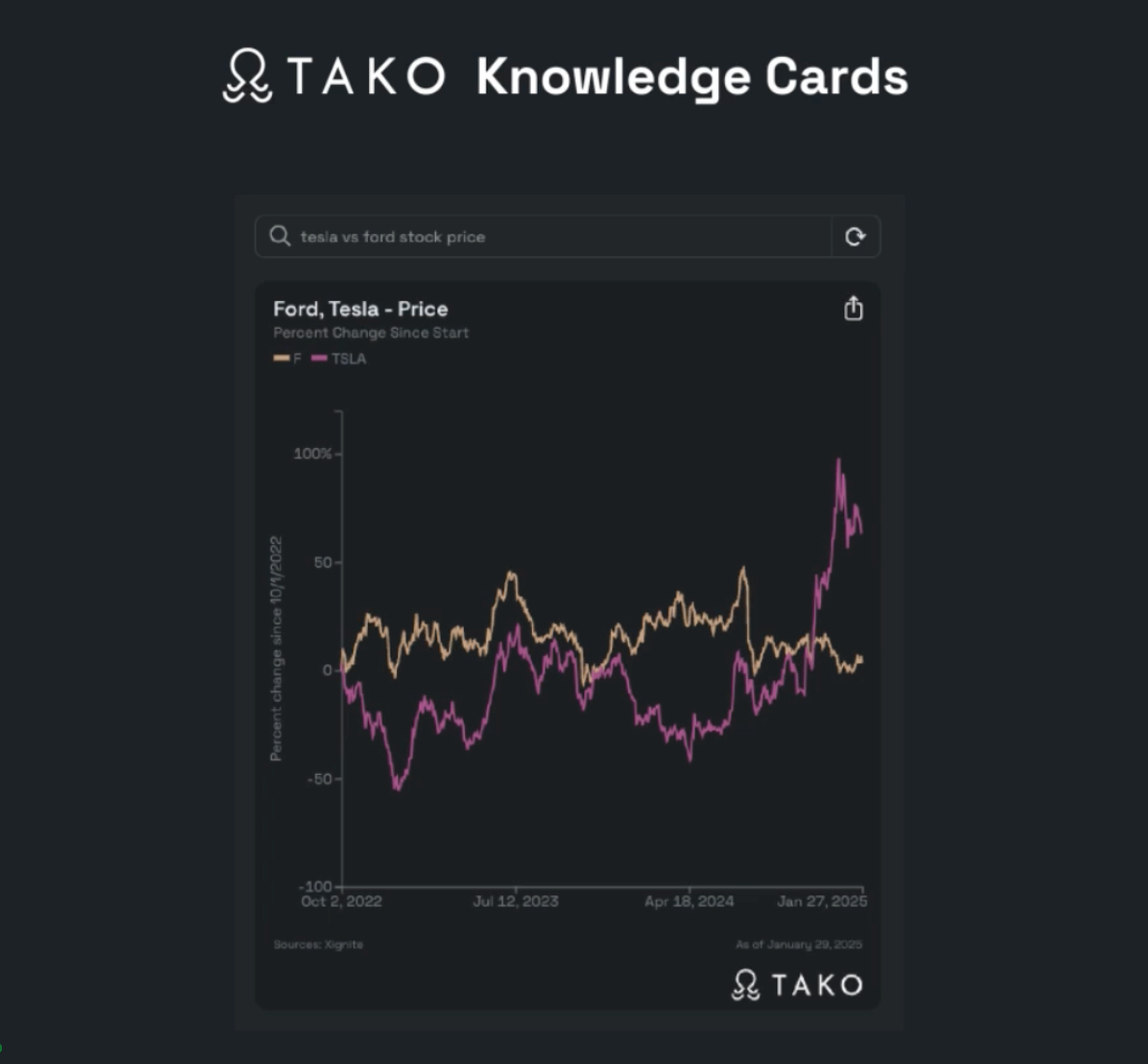
However, this ambition faced a significant challenge: conventional GPU-based inference systems could not process massive datasets quickly enough to generate real-time user interfaces.
Unlocking New Features: Related Search
Tako now runs the Llama 3.3-70B model on Cerebras’s inference API to help answer customers questions with accurate, real-time knowledge cards almost as fast as they ask them. With increased inference speeds, Tako was able to generate knowledge cards at scale with large amounts of data without sacrificing user experience. Not only did improved inference speeds unlock new features like Related Search, Cerebras made the core search product experience better.
Since integrating Cerebras, Tako has seen their median and P95 search latency reduced by 60%. P95, or the 95th percentile latency, measures the time it takes to process 95% of user requests, highlighting the worst-case performance for most users.
With Cerebras, Tako delivers factual and interactive data-driven solutions that transform how we access and utilize the world’s knowledge.