Feb 25 2025
Extending LLM context with 99% less training tokens
Long-context capability is essential for LLM performance and highly desirable for real-world applications like document summarization, retrieval-augmented generation (RAG), and conversational AI. However, training LLMs to handle long contexts is computationally expensive—typically requiring hundreds of billions of tokens to extend a model’s context length. For example, Llama3.1 extended its context to 128K tokens using an 800B-token training run. In this blogpost, we present an efficient context extension recipe by leveraging the new features in Cerebras Model Zoo Release 2.4. In particular, we demonstrate that our recipe can extend Llama3-8B-Instruct to have similar long context performance as Llama-3.1-8B-Instruct while needing ~10B training tokens for the context extension phase. We release the training recipe and the synthetic long instruction-following data on the HuggingFace Hub.
Results summary
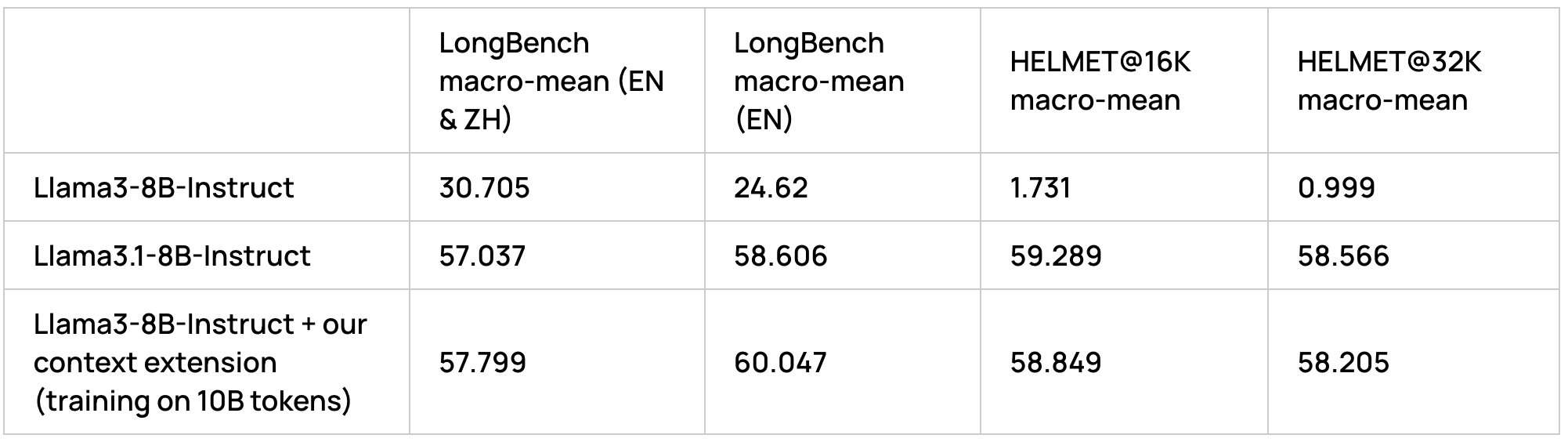
We evaluate LLM long context capabilities using two challenging benchmarks – LongBench [Bai et al.] and HELMET [Yen et al.]. As the table below shows, Llama3-8B-Instruct has poor long context capabilities but with our recipe we are able to match and even improve on Llama 3.1-8B-Instruct’s long context capabilities with a very most modest compute of ~10B tokens.
Methods
In the following sections, we discuss the ML techniques that enabled us to achieve this accuracy level with a modest training budget.
Synthetic long-context instruction tuning data generation
Our initial observation was that the existing long-context fine-tuning data in the community lacked the quality needed to effectively train the model for robust long-context capabilities. To address this, we developed and open-sourced several high-quality synthetic long-context SFT datasets, enabling us to achieve highly accurate long-context support in an efficient manner.
Retrieval Augmented Fine-Tuning (RAFT)
Our synthetic long-context data is based on an approach introduced by [Zhang et al., 2024] called Retrieval Augmented Fine-Tuning (RAFT). Many existing question-answering datasets contain examples of (passage, question, answer). However, this setting differs from real-life inputs at inference-time in RAG applications, as noted in [Zhang et al., 2024]. Instead the model will have to decipher through multiple passages of varying relevance that are retrieved, each of which could contain the information required to answer the question. Therefore they propose to add distractor passages during training, so that the model is not just trained on single passage/question pairs and then expected to distinguish between similar passages at inference-time.
We adopted elements of the RAFT approach for our long-context SFT datasets. We are not explicitly performing RAG, but this setting is also perfect for forcing a model to fully utilize the full context window. For each example in the dataset, we convert (passage, question, answer) into (true_passage, distractor_passage_0, …, distractor_passage_k, question, answer). The distractors are the passages with the highest similarity to the true passages, as measured by their embeddings. We shuffle the true passage into a random position in the context, so the model has to work hard to distinguish between the similar passages and select the right information.
Implementation
We perform RAFT-style augmentation on a few datasets. We took inspiration from Nvidia’s ChatQA work [Liu et al., 2024] for some of the choices, specifically NarrativeQA and Synthetic-ConvQA. NarrativeQA is a classic long-context dataset that contains books and movie scripts, with human-written questions that require full understanding of the entire passage. Synthetic-ConvQA is based on GPT-3.5 dialogue grounded on documents filtered from CommonCrawl, and was released in the ChatQA paper.
Our processing for Synthetic-ConvQA followed the methodology outlined in the section above, but for NarrativeQA we perform a slightly different procedure. In the variation for NarrativeQA, we create two clustering assignments, one based on the questions, and one based on the passages. For each example in the dataset, we add other examples from the same passage cluster, and also examples from the question cluster. When we add the examples, we add both the passages and question/answer pairs. The initial RAFT methodology only uses one question/answer pair with all the passages, so the additional question/answer pairs in this alteration allow more training signal to come from one example. In this method – and in standard RAFT – we add examples until we reach the maximal sequence length of 32k tokens.
We also wanted to produce data that requires aggregating information across multiple sources to answer a single question. Our RAFT-augmented datasets would still have the answer contained in a single passage. We used the existing RAG-TGE dataset, which natively requires the model to answer a question based on multiple passages. We further apply the RAFT augmentation on this data to make it more difficult for the model to parse the full context.
Additional techniques
We also create some additional datasets to improve long-context capabilities, and address specific weaknesses in the model:
- ‘Syntactic question’ data
Another way to force the model to utilize all parts of the context is to create synthetic tasks that require the model to aggregate information across the full context. We take the RAFT-augmented Synthetic-ConvQA dataset and create five synthetic question/answer pairs for each example: (1) Does the word ‘X’ occur in the passage? (2) How often does the word ‘X’ occur in the passage? (3) Does the phrase ‘X’ occur in the passage? (4) How often does the phrase ‘X’ occur in the passage? and (5) Where does the word ‘X’ occur in the passage?
Phrases in this context are 4-grams, and to create our questions we randomly select words and phrases that comprise less than 10% of the total words or phrases. For the positional information in the fifth question, we bin the answers to which third of the passage it appears. - ‘Translation’ data
We also translated the RAFT-augmented RAG-TGE dataset to Chinese, as we noticed that our performance in Chinese subsets of the LongBench benchmark was declining after fine-tuning. To accomplish this we simply prompted Llama3.1-70B to translate the data to Chinese.
Train-time token position ID shifting
Recently, there have been attempts in the community to develop a compute-efficient context extension approach that would allow training at lower sequence lengths than the eventual target context length, such as PoSE [Zhu et al.] and CREAM [Wu et al.]. The main idea of these methods, which we refer to as “token position ID shifting” methods here, is to modify the RoPE computation process such that the relative distances between tokens in a sequence are larger than actual distances between them in the sequence. One way to do that could be, while keeping the data itself intact, modify the position IDs of tokens during RoPE computation such that instead of [0 … N-1], the position ID vector would effectively be [0 … N*-1] where N is the actual sequence length of the data and N* is the target sequence length that we would like to extend to.
As an example, imagine an input consisting of 8 tokens {t_i}. Normally, one would assign position IDs to that sequence to be a contiguous sequence {p_i}. [Zhu et al.] propose to divide the input sequence into segments and shifting every segment’s position IDs by a certain bias value with regards to the previous segment, with biases sampled from a uniform distribution. For example, if we split the {t_i} into two segments of length 4:
The first segment positions can be kept as is, as we’re only interested in relative distances, and the value of b is chosen such that p_7 + b < N*. [Zhu et al.] also propose to shift the token content of the sequence accordingly, but we’re considering a simplified version of the method where only the position ID vector is modified.
In a similar method, [Wu et al.] propose to split the input into 3 segments (head, middle, tail) and keep the first and last segment’s IDs continuous (starting from 0 and ending with N*-1, respectively) while sampling the start and end indices of the middle segment from a truncated Gaussian distribution:
Here, p* = N* – 1 is the target simulated last token index, and both the head and tail segments have a length of 2. While both [Wu et al.] and [Zhu et al.] these works also propose to modify the original data (tokens {t_i}) by stitching together segments from sequences of actual length N*, we only consider modifications of position IDs as outlined above. Furthermore, we found the simplified version of CREAM [Wu et al.] to outperform PoSE [Zhu et al.] when used during continued pre-training.
RoPE position extrapolation
There have been multiple works suggesting modifications to the RoPE mechanism to enable extrapolation to longer context with minimal fine-tuning (see [Lu et al.] for a detailed comparison of approaches). Here, we employ a simple strategy of adjusting the base frequency parameter of RoPE uniformly across all hidden dimensions. Following [Gao et al.], we set a base frequency value of 8e6 instead of 5e5 (the value used in the original model). A proper comparison of more advanced RoPE methods is a topic of future work.
Training pipeline
Our training recipe consists of a continued pre-training (CPT) stage with long context data (32K actual maximum sequence length) followed by two supervised fine-tuning (SFT) stages: first, using short-context high-quality instruction tuning data (short SFT stage) followed by a long-context instruction tuning stage primarily utilizing our synthetically generated data. Below is the training recipe for the corresponding stages of our pipeline (data mixes and hyper-parameter settings):
Stage 1. CPT@32K
Data: We have used the LongDataCollections data collection (pre-training subset) for this stage pre-processed to have maximal sequence length of 32K.
Training hyper-parameters:
- ~7.4B tokens total, batch size 2.95M tokens,
- linear learning rate warmup to 5e-6 first 8% of steps, then cosine decay to 1e-8,
- zero weight decay.
Stage 2. SFT@8K
Instruction tuning stage on high-quality SFT data mix.
Data mix:
- 70% Magpie-Pro-300K-Filtered
- 15% OpenMathInstruct-2
- 15% SystemChat
Training hyper-parameters:
- ~1B tokens total, batch size 1M tokens,
- linear learning rate warmup to 5e-6 first 7.5% of steps, then cosine decay to 1e-8,
- zero weight decay.
Stage 3. SFT@32K
Long-context instruction tuning stage to improve performance over wide context.
Data mix:
- 77.5% Cerebras synthetic data:
- 50% RAFT-augmented ConvQA,
- 7.5% RAFT-augmented RAG-TGE,
- 7.5% RAFT-augmented RAG-TGE in Chinese,
- 7.5% RAFT-augmented ConvQA with syntactic questions,
- 5.0% Distractor-augmented NarrativeQA
- 22.5% Open-source long instruction-tuning datasets:
- 7.5% LongDataCollections (SFT subset – BookSum, Multi-passage QA),
- 7.5% LongWriter6k,
- 7.5% LongAlpaca12k
Training hyper-parameters:
- ~1.76B tokens total, batch size 1.96M,
- linear learning rate warmup to 1e-6 first 6.6% of steps, then cosine decay to 1e-8,
- zero weight decay.
Together, these three training stages constitute a training budget of about ~10B tokens.
Our decision to not use weight decay is based on existing recipes [Peng et al.], and we have also found that using a lower peak learning rate during the last long SFT stage yields better long-context performance results overall.
Evaluation results
We adopt the recently released HELMET benchmark [Yen et al.] to measure long-context performance of models, as it encompasses a diverse set of tasks (retrieval, multi-hop question answering, few-short learning, reranking and other) at fixed context lengths. Our choice of evaluation benchmarks is backed by observations that perplexity does not provide a good measure of overall model performance in long context tasks [Fang et al., Yen et al.], and synthetic needle-in-a-haystack (NIAH) style tasks are limited in their scope.
First, we have measured performance of Llama3-8B-Instruct and Llama3.1-8B-Instruct on HELMET tasks with 16K context length and, as expected, observed near-zero performance of Llama3:

We did not include the HELMET citation task category, as we found performance of 8B-sized models is generally low in that category.
Next, to ablate the effect of our SFT data mixes, we have trained Llama3-8B-Instruct with the 3 following recipes:
- only long SFT data mix with 32K sequence length,
- only short SFT with position ID shifting (original sequence length 8K, shifted to target sequence length of 32K),
- short SFT with position ID shifting followed by long SFT;
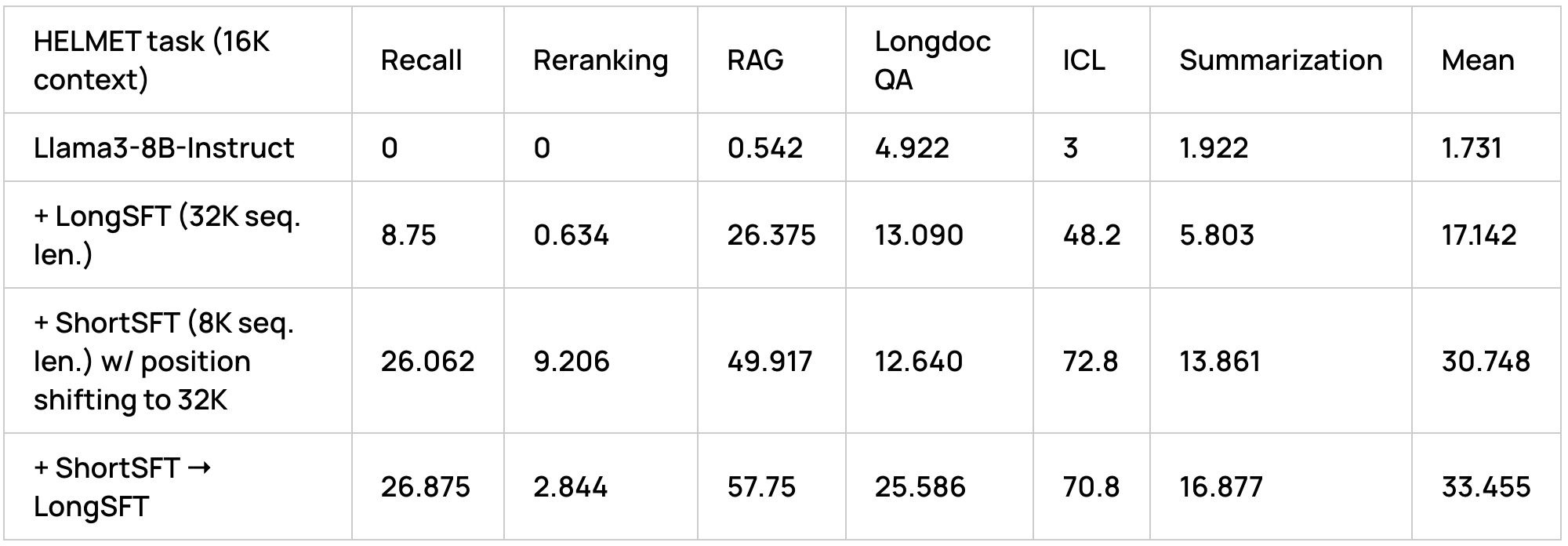
We observed dramatic improvements w.r.t baseline with both long SFT and short SFT with position shifting (with the latter yielding stronger results on almost all task categories), and a further improvement with a two-stage training pipeline with short SFT stage with position shifting followed by a long SFT training round. Interestingly, while seeing an improvement in most task categories, we also observed a degradation in reranking performance as a result of long SFT (after short SFT), which might suggest that our long SFT data mix could benefit from including datasets that specifically target reranking.
With the above results we have established the benefit of both our long-SFT synthetic data and token position ID shifting for long-context scenarios. However, the performance metric numbers are still far from the level of Llama3.1-8B-Instruct. To address this discrepancy, we adopted a longer training schedule with a continued long-context pre-training phase followed by SFT stages (short SFT followed by long SFT as before). Additionally, following [Gao et al.], we perform position extrapolation by increasing the RoPE base frequency of Llama3-8B-Instruct to a value of 8×1e6 at the start of training.
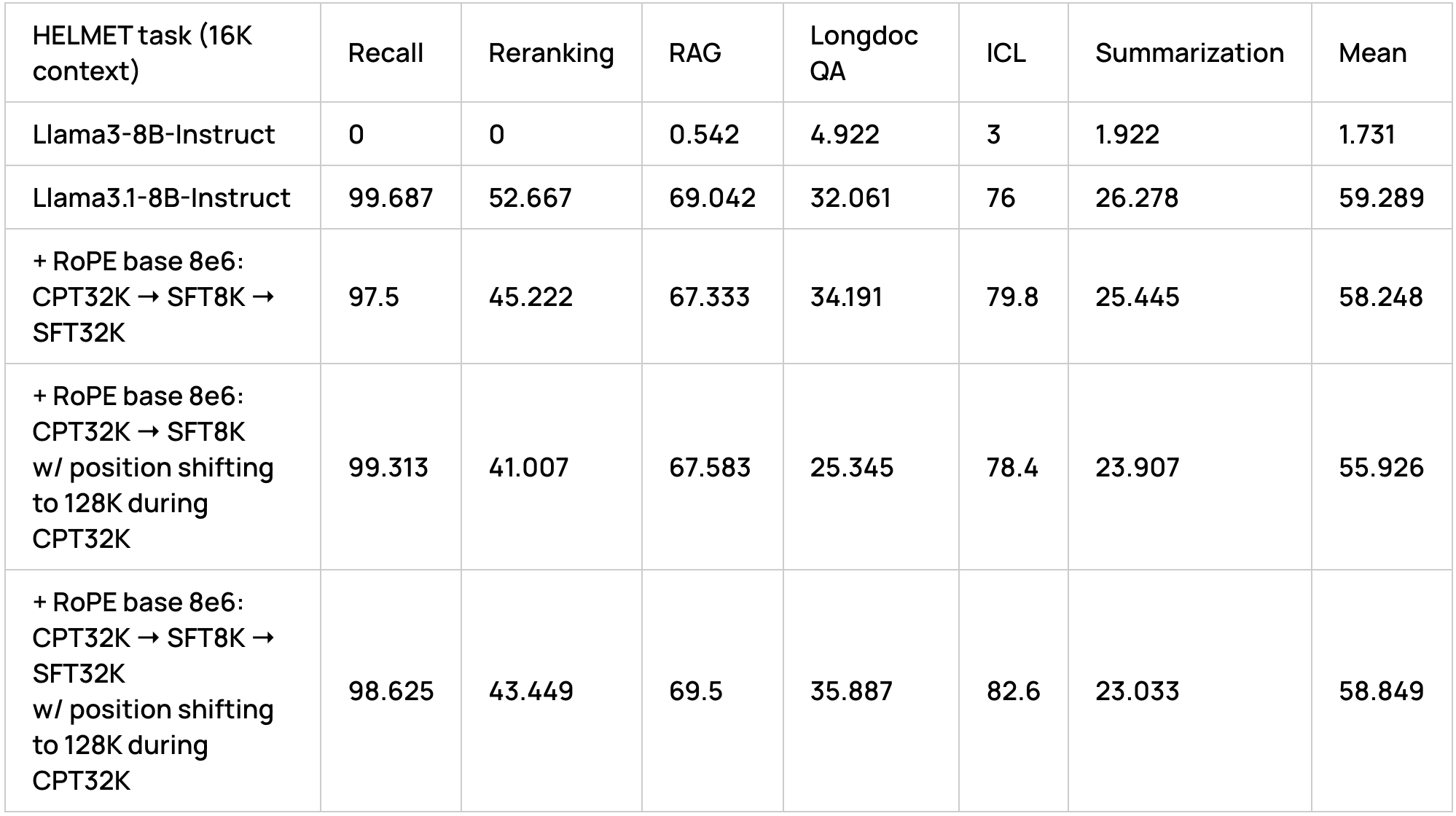
These results show that our full training schedule with continued pre-training for ~7B tokens followed by a short SFT and long SFT stage (each for ~1B tokens) brought about performance levels comparable to Llama3.1-8B-Instruct while only requiring a fraction of training tokens specifically for the context extension phase itself compared to Llama3.1-8B-Instruct.
Additionally, we found that applying position shifting during the continued pre-training stage with target sequence lengths greater than the test-time input length yielded a performance boost compared to the pipeline without position ID shifting. Interestingly, [Gao et al.] also observed that training on data of sequence length longer than than testing data improved overall performance.
Moreover, unlike [Gao et al.], we did observe a performance boost from synthetic long SFT data (specifically on Longdoc QA, ICL and RAG tasks). However, while our best configuration outperformed Llama3.1-8B-Instruct on Longdoc QA, RAG and ICL, we found our models falling behind on reranking and summarization tasks. This could perhaps be addressed by a better long SFT data mix, and is a subject of our future work.
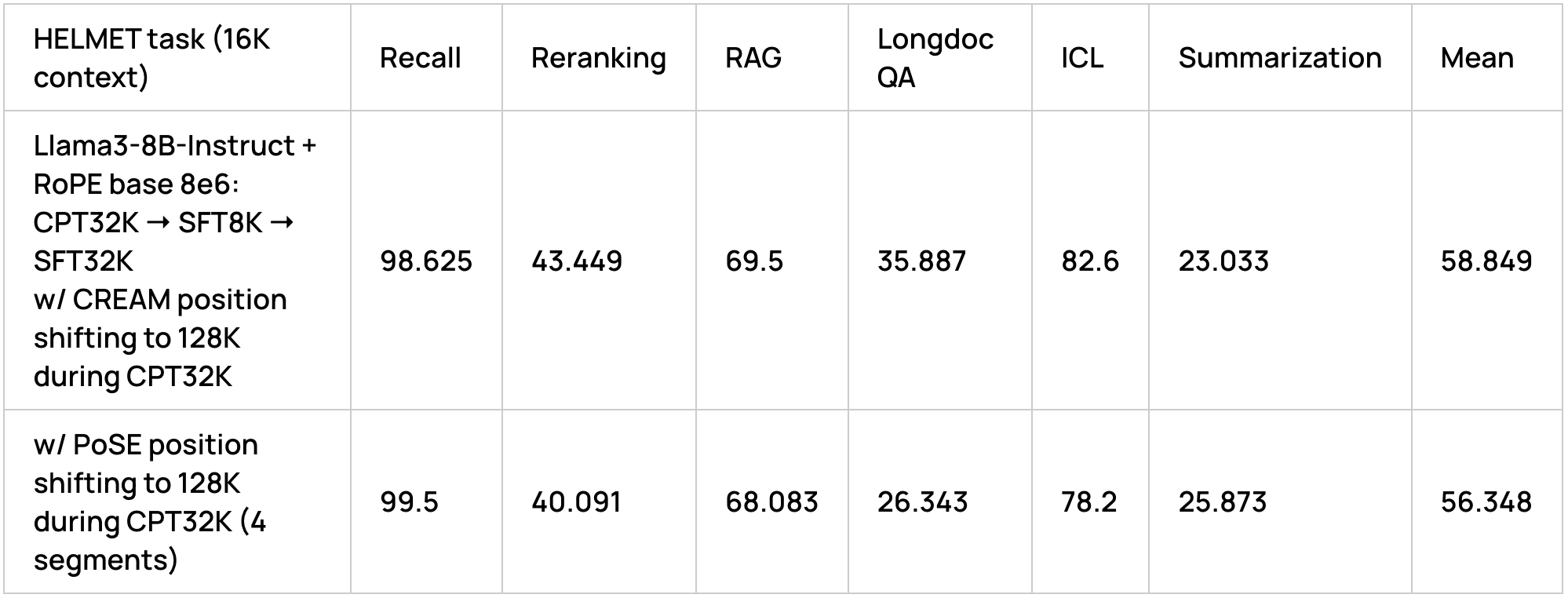
The choice of position shifting strategy proposed by CREAM was based on empirical observations of better performance compared to PoSE (when applying PoSE, we shifted position IDs in a randomly selected half of the samples in the batch, while the rest of the batch samples were not modified):
To make sure we were not overfitting our design choices to HELMET evaluation scores, we have also tested our models on another popular long-context evaluation benchmark, LongBench [Bai et al.], which contains task categories not present in HELMET, such as code completion and non-English tasks:
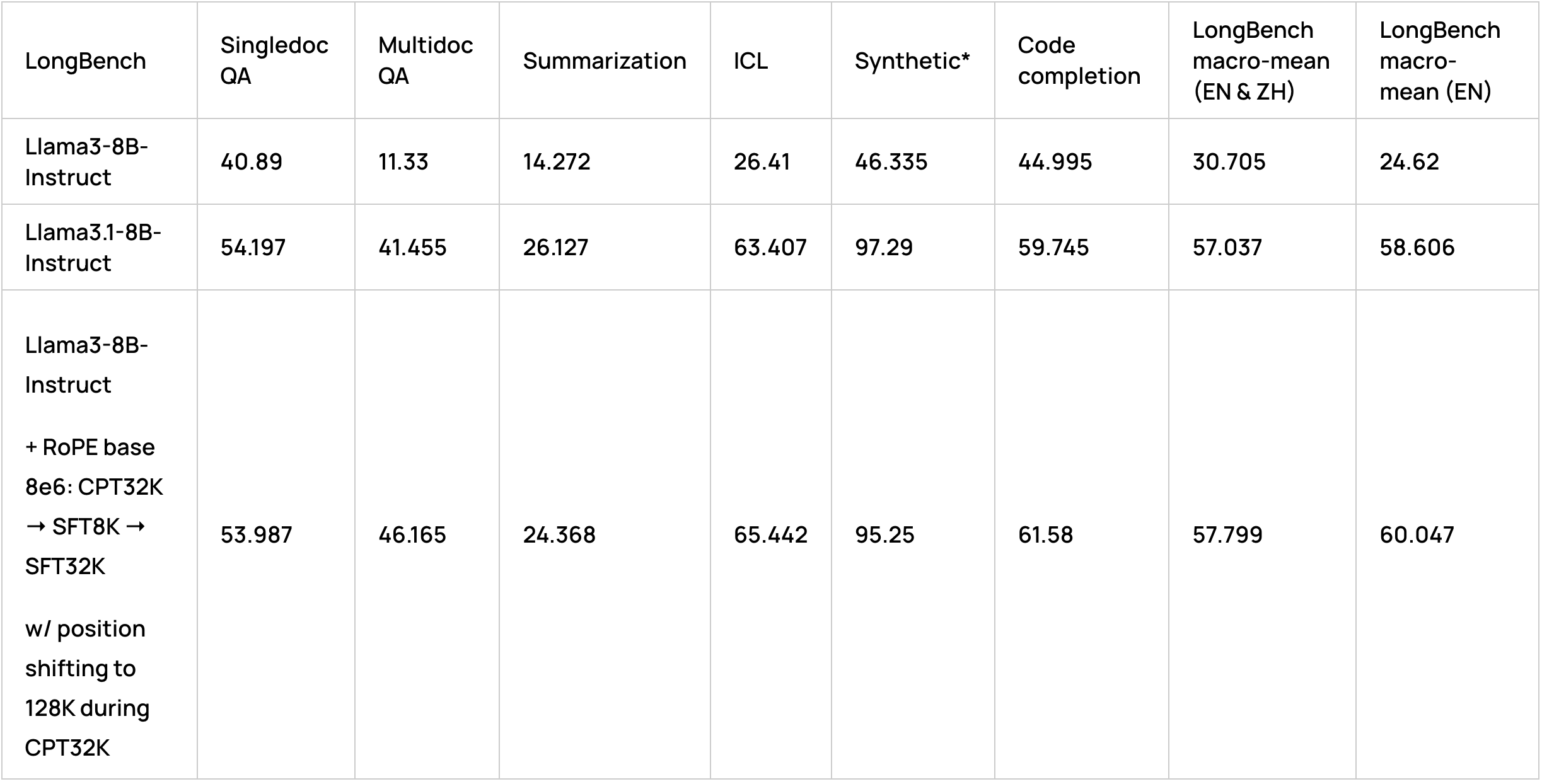
We did not include the passage retrieval task to calculate synthetic category score, as all 8B models show poor performance in it.

Hence, we were able to outperform Llama3.1-8B-Instruct on the LongBench benchmark in both English and English+Chinese tasks. We also were able to get performance on HELMET with context length of 32k on par with Llama3.1-8B-Instruct.
Conclusion
We demonstrate context extension of Llama3-8B-Instruct with a training budget under 10B tokens (80x less tokens than originally used for Llama3.1-8B context extension) that matches performance of Llama3.1-8B-Instruct on HELMET (at 16K and 32K context length) and LongBench benchmarks. Our recipe consists of a combination of synthetic long-context data generated with RAFT; position ID shifting in RoPE to simulate longer input sequences; and adjusting of the RoPE base frequency for context length extrapolation. We have carried out ablations to demonstrate the impact of individual components of our recipe on final model performance. Future work would involve effective synthetic data generation at 128K+ lengths using agentic pipelines [Qwen team, 2025] and scaling up the continued pre-training lengths to 256K and larger. Our context extension recipe is built on features available in Cerebras Model Zoo (Release 2.4).
Contributors: Ivan Lazarevich, David Bick, Harsh Gupta, Srinjoy Mukherjee, Nishit Neema, Gokul Ramakrishnan, Ganesh Venkatesh.
References
- Zhu, D., Yang, N., Wang, L., Song, Y., Wu, W., Wei, F., & Li, S. (2023). Pose: Efficient context window extension of llms via positional skip-wise training. arXiv preprint arXiv:2309.10400.
- Wu, T., Zhao, Y., & Zheng, Z. (2024). Never Miss A Beat: An Efficient Recipe for Context Window Extension of Large Language Models with Consistent” Middle” Enhancement. arXiv preprint arXiv:2406.07138.
- Yen, H., Gao, T., Hou, M., Ding, K., Fleischer, D., Izsak, P., … & Chen, D. (2024). Helmet: How to evaluate long-context language models effectively and thoroughly. arXiv preprint arXiv:2410.02694.
- Fang, L., Wang, Y., Liu, Z., Zhang, C., Jegelka, S., Gao, J., … & Wang, Y. (2024). What is Wrong with Perplexity for Long-context Language Modeling?. arXiv preprint arXiv:2410.23771.
- Gao, T., Wettig, A., Yen, H., & Chen, D. (2024). How to train long-context language models (effectively). arXiv preprint arXiv:2410.02660.
- Bai, Y., Lv, X., Zhang, J., Lyu, H., Tang, J., Huang, Z., … & Li, J. (2023). Longbench: A bilingual, multitask benchmark for long context understanding. arXiv preprint arXiv:2308.14508.
- Tianjun Zhang and Shishir G. Patil and Naman Jain and Sheng Shen and Matei Zaharia and Ion Stoica and Joseph E. Gonzalez (2024). RAFT: Adapting Language Model to Domain Specific RAG. arXiv preprint arXiv:2403.10131
- Zihan Liu and Wei Ping and Rajarshi Roy and Peng Xu and Chankyu Lee and Mohammad Shoeybi and Bryan Catanzaro (2024). ChatQA: Surpassing GPT-4 on Conversational QA and RAG. arXiv preprint arXiv:2401.10225
- Peng, B., Quesnelle, J., Fan, H., & Shippole, E. (2023). Yarn: Efficient context window extension of large language models. arXiv preprint arXiv:2309.00071.
- Qwen team, https://qwenlm.github.io/blog/qwen-agent-2405/, 2025.
- Lu, Y., Yan, J. N., Yang, S., Chiu, J. T., Ren, S., Yuan, F., … & Rush, A. M. (2024). A controlled study on long context extension and generalization in llms. arXiv preprint arXiv:2409.12181.