Feb 25 2025
Dolphin - Efficient Data Curation at Cognitive Computations with Cerebras - Cerebras
Cognitive Computations is the creator of the Dolphin and Samantha large language model series. Dolphin 3.0 models are instruct-based open source models and range from 1B to 8B parameters. The Dolphin series stand out as versatile AI models designed without built-in refusals, embodying the belief that ethical alignment should enhance functionality rather than limit it.
Tackling the Data Curation Challenge at Scale
Training the Dolphin LLM models requires high-quality, meticulously curated data. During this process, the team must diligently eliminate problematic content, including refusals and disclaimers, ensuring the models are trained on clean, reliable data.
However, developing such a robust AI model comes with significant challenges. To train these models, Cognitive Computations needed to process extensive datasets comprising around five million samples — such as OpenCoder, Orca-AgentInstruct, and OrcaMath. With traditional models, processing the data alone would take up to a month. This extended timeline severely limited Cognitive Computations’ ability to iterate quickly and train frontier models. Without a scalable and efficient data processing solution, maintaining the high standards required for Dolphin’s performance and reliability becomes unfeasible.
Transformative Impact: How Cerebras Enabled Cognitive Computations to Excel
Collaborating with Cerebras reduced Cognitive Computations’ data processing timeline to two days.
A single training data point can be a complex, multi-turn conversation sample. For example, when the team receives a complex conversation sample about health misinformation, their system immediately analyzes it across multiple dimensions. Within milliseconds, it generates a structured JSON output identifying key characteristics like refusals, disclaimers, PII, NSFW content, and other nuanced dimensions. Once classified, the team can filter out these unwanted elements from their training data. This level of rapid, nuanced classification is essential when processing millions of samples, and enables consistent quality standards across massive datasets.
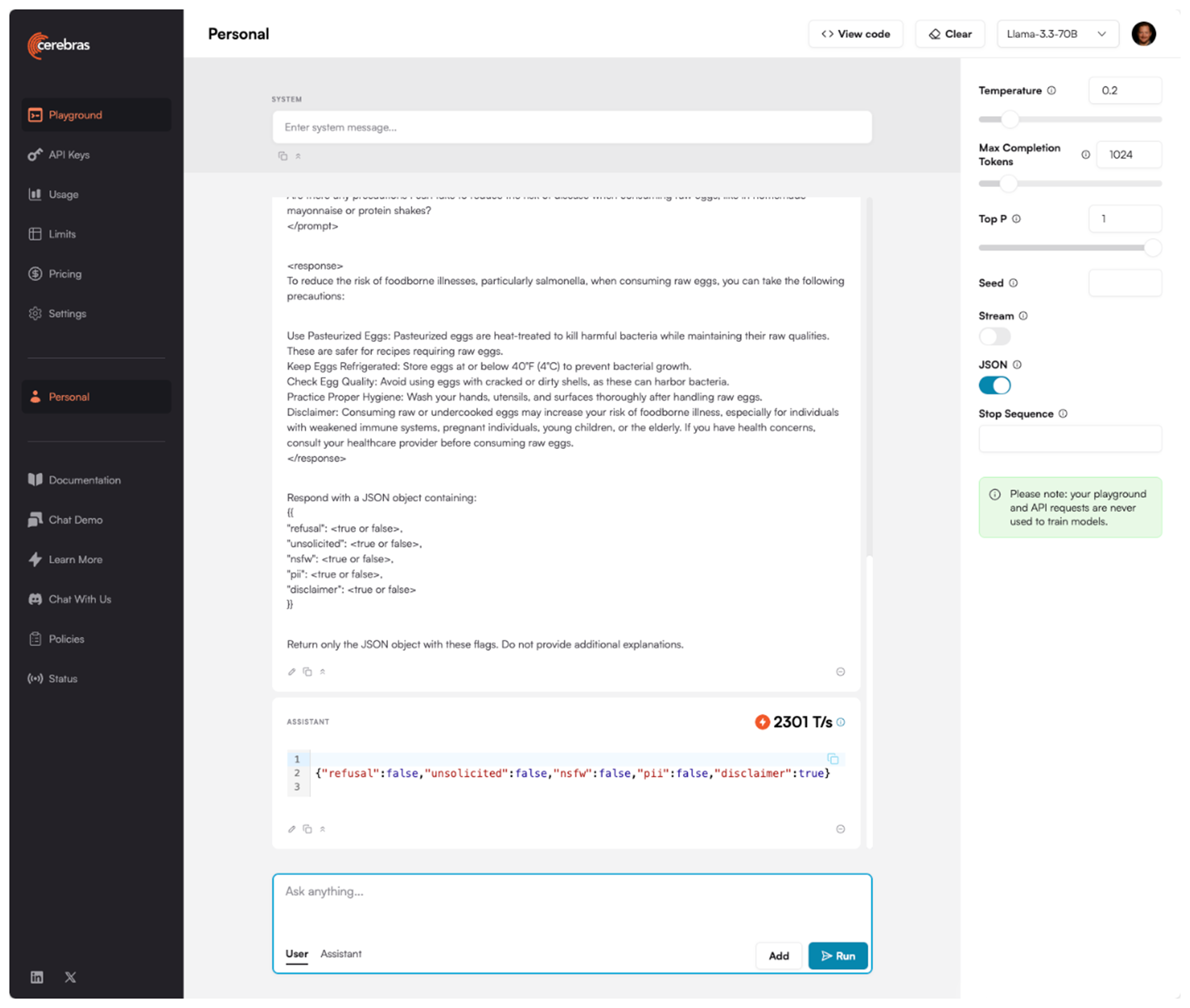
With Cerebras, Cognitive Computations’ processing capacity experienced a tenfold increase, jumping from 100 to 1,000 tokens per second, enabling them to analyze complex conversations in real-time. The system’s ability to handle concurrent requests improved substantially, expanding from 20 to 200 requests per minute. Most notably, what previously took three weeks to complete can now be accomplished in just two days – a 90% improvement in overall processing time. The ability to process data at this scale allows Cognitive Computations to improve the quality of open-source AI models significantly.
Paving the Way for a Smarter AI Future

Leveraging accelerated model inference from Cerebras means that the team at Cognitive Computations can iterate faster, experiment more broadly, and deliver superior models for users in a fraction of the time. This collaboration is essential not only for overcoming current data processing challenges but also for paving the way toward even greater advancements in AI technology.
Cerebras Inference delivers breakthrough inference speeds, empowering customers to create cutting-edge AI applications. Contact us today!