Cerebras is proud to introduce CePO (Cerebras Planning and Optimization), a framework that adds sophisticated reasoning capabilities to the Llama family of models. Through test-time computation techniques, we enable Llama to tackle complex reasoning tasks with unprecedented accuracy. While models like OpenAI o1 and Alibaba QwQ have shown how additional computation at inference time can dramatically improve problem-solving capabilities [1], we’re now bringing these advances to Llama – the world’s most popular open-source LLM.
By applying CePO to Llama 3.3-70B [3], we enable it to significantly surpass Llama-405B across challenging benchmarks in coding, math, and reasoning tasks. Running on Cerebras hardware, we achieve interactive performance of approximately 100 tokens/second – a first among test-time reasoning models.

Meta released Llama-3.3 70B with the goal of narrowing the accuracy gap with Llama-3.1 405B. By integrating CePO, we empower Llama-3.3 70B to surpass Llama-3.1 405B in accuracy, demonstrating that our approach provides greater value as the quality of LLMs improve. While CePO helped Llama-3.1 70B to nearly match the accuracy of Llama-3.1 405B on MMLU-Pro (Math), GPQA and CRUX, it propels Llama-3.3 70B to decisively surpass Llama-3.1 405B by several percentage points!
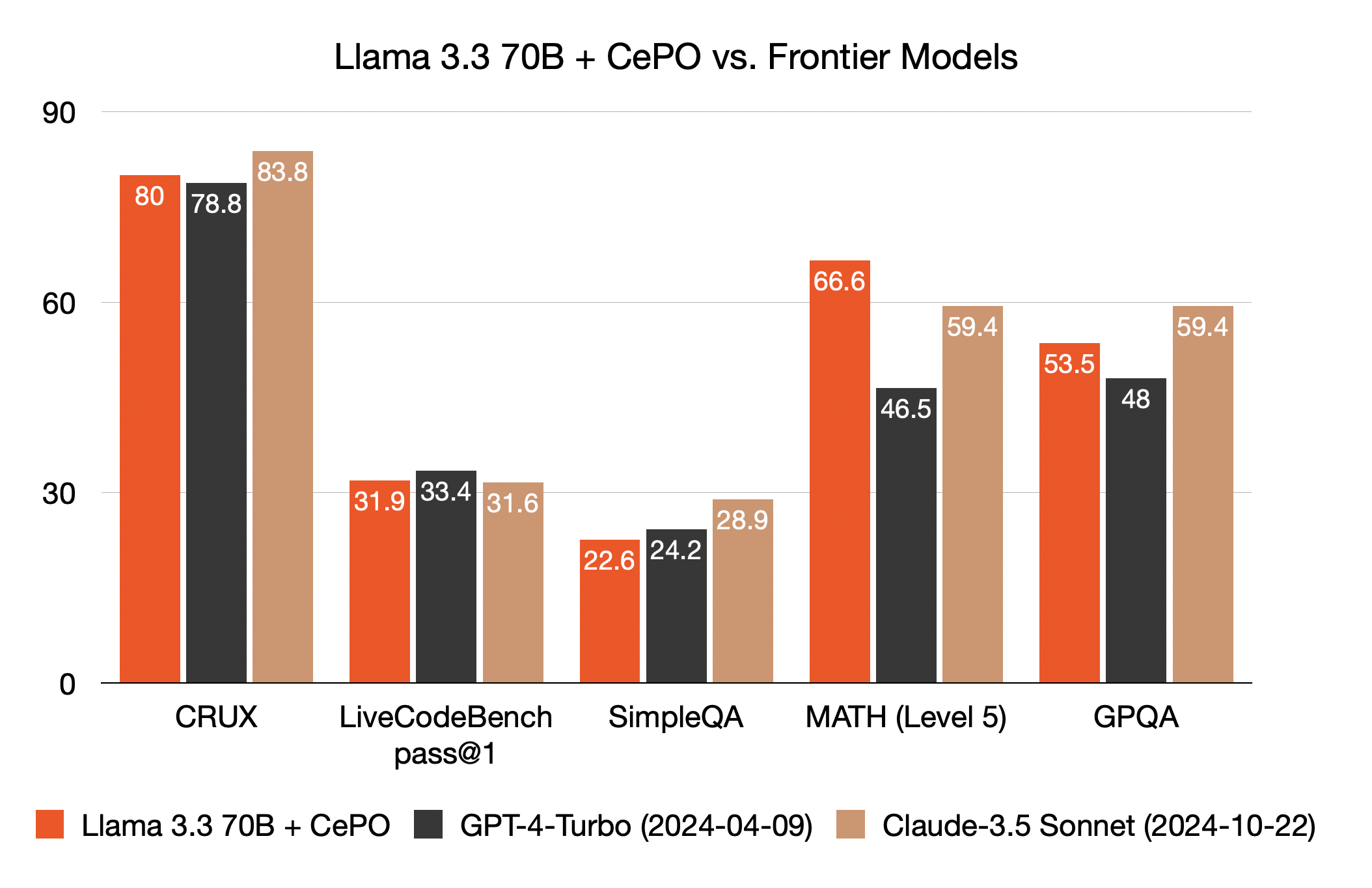
We also measured Llama 3.3 70B with CePO against GPT-4 Turbo and Sonnet 3.5. Thanks to CePO, Llama 3.3 70B reached comparable performance in CRUX, LiveCodeBench, GPQA and significantly outperformed in MATH.
How CePO Works
CePO is built based on three key insights:
1. Step-by-step reasoning: An LLM has a higher chance of successfully tackling complex questions by breaking them into simple steps that it can execute correctly with high confidence.
2. Comparison instead of Verification: Off-the-shelf LLMs struggle with self-refinement, showing both false positives and negatives. However, they excel at comparing solutions to identify inconsistencies and determine whether both solutions are correct or at least one is incorrect.
3. Intuitive Output Format: LLMs perform better with numerical ratings or structured outputs when the format is demonstrated multiple times and clearly emphasizes expectations. For example, using “Rating: <number>” instead of just requesting a numerical rating.
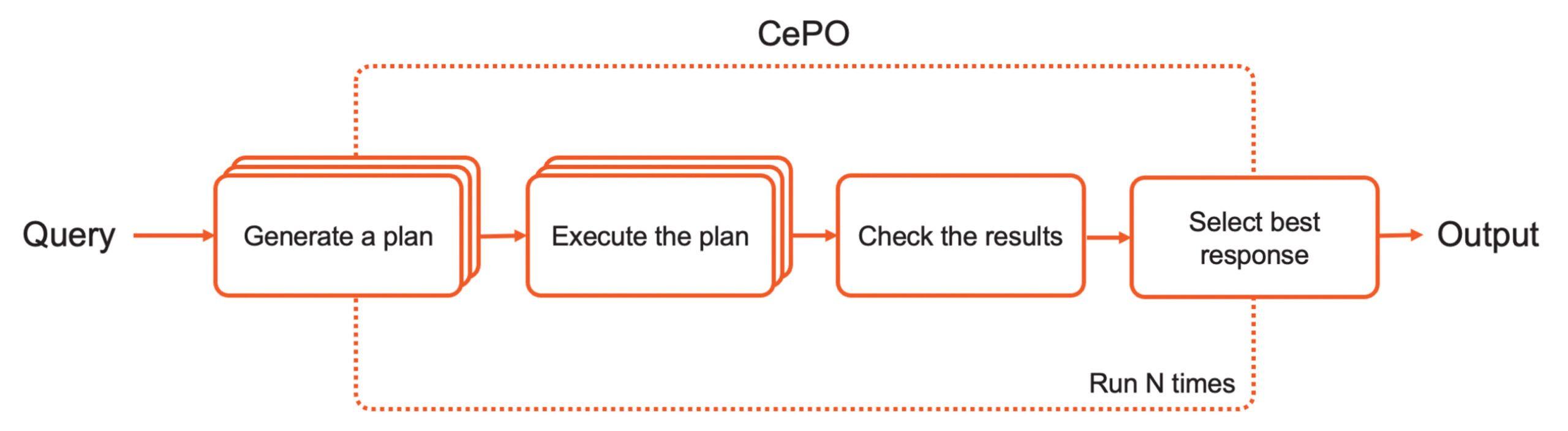
The CePO pipeline consists of four stages:
- The LLM produces a plan to solve a given problem step-by-step
- The LLM executes the plan multiple times to produce multiple responses
- The model analyzes responses to identify inconsistencies across executions, helping catch and correct mistakes
- Solutions are wrapped in a Best-of-N framework with structured confidence scoring
In general, CePO consumes 10-20x more inference tokens than one-shot approaches. However, when running on Cerebras hardware, we achieve equivalent performance of about 100 tokens/second – comparable to leading models like GPT-4 Turbo and Claude 3.5 Sonnet.
Real-World Examples
Strawberry Test v2.0
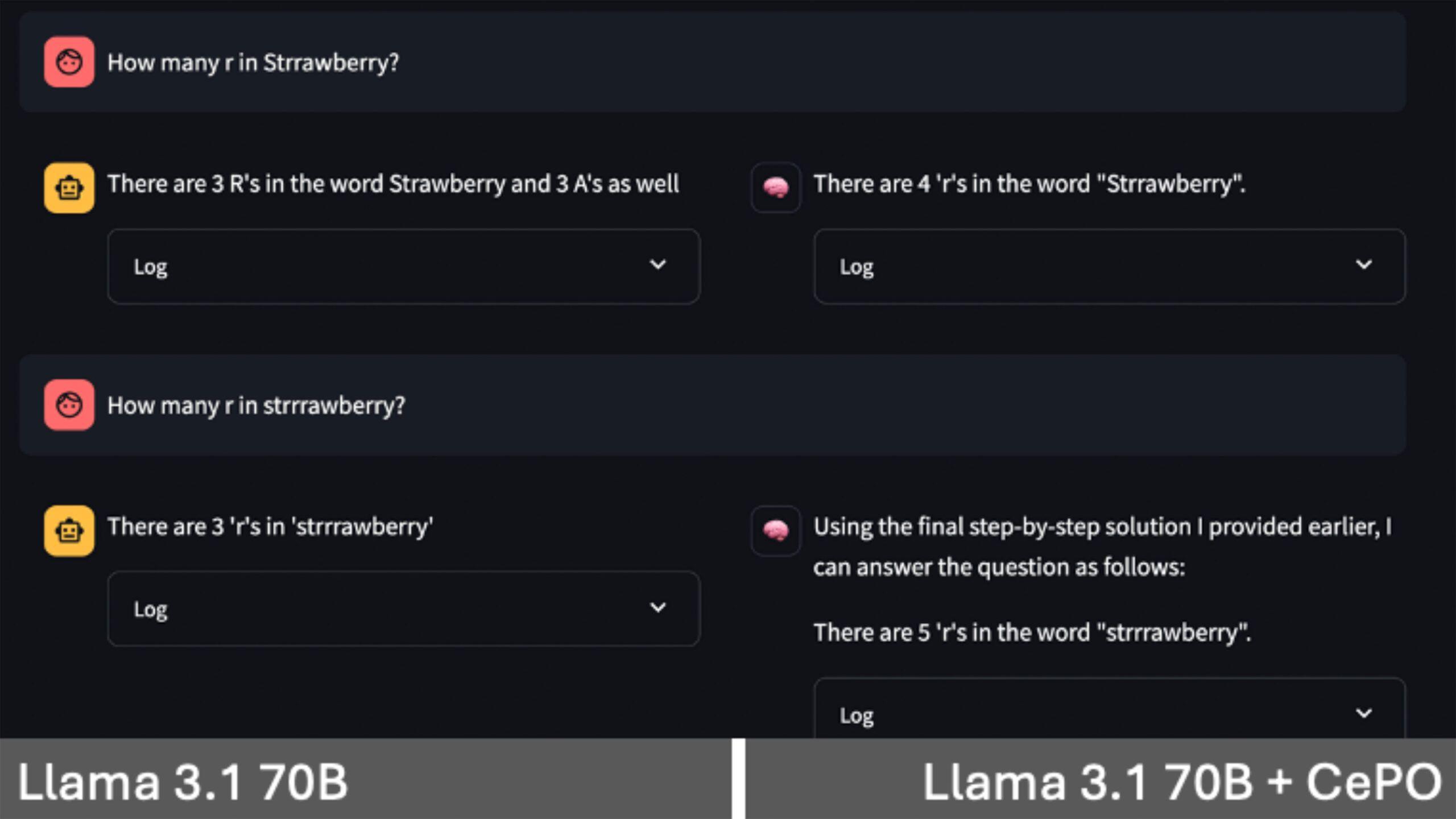
The strawberry test is a popular test to see if models memorize answers or evaluate based on first principles. Strawberry correctly spelt has 3 ‘r’s. When more ‘r’s are added, most models get it wrong since it simply remembers the answer as 3. With CePO, the model checks its own work and supplies the correct answer.
Russian Roulette with a Twist
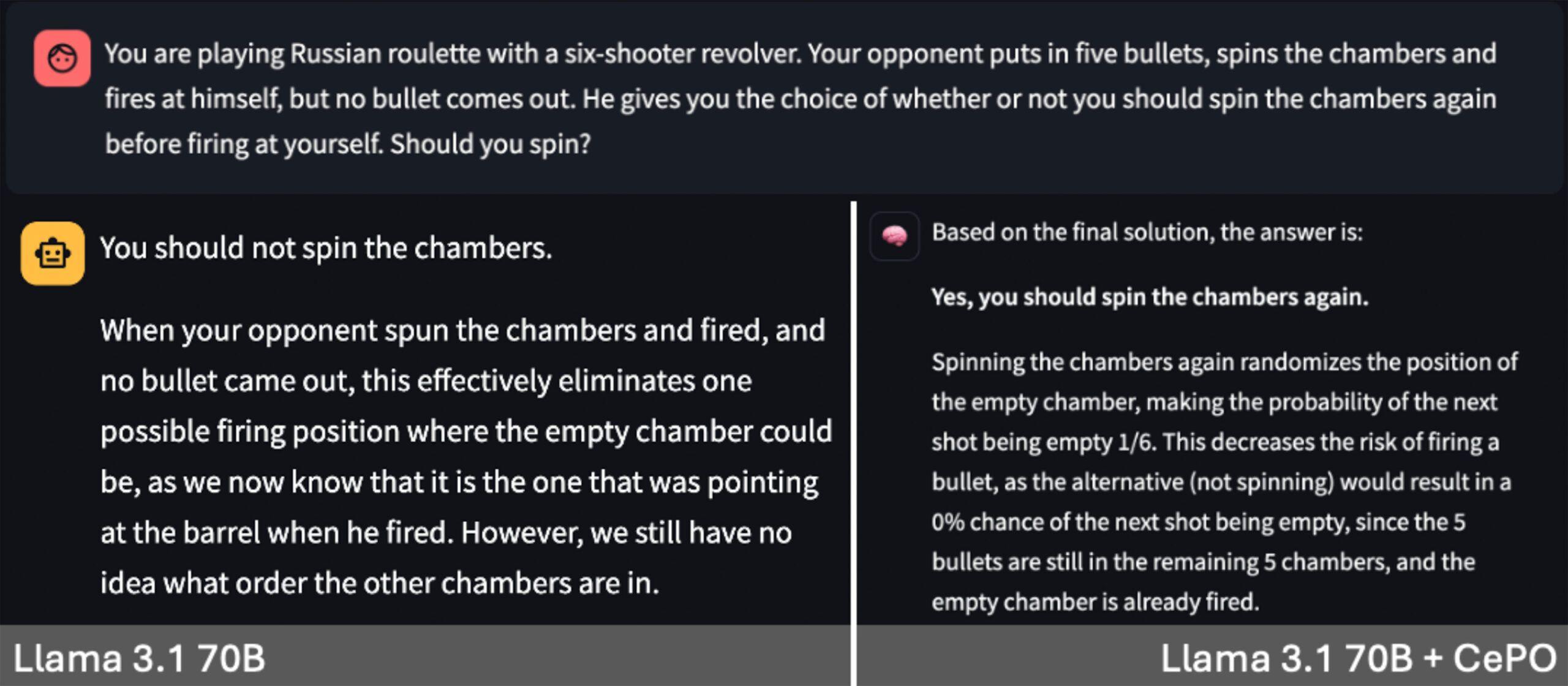
This reasoning puzzle again tests a model’s ability to evaluate based on first principles instead of going with conventional wisdom/memorized answers. We modify the popular Russian Roulette problem as follows – instead of one bullet, we add five bullets to the gun, changing which option provides a higher chance of survival. Here again, the model tends to get it wrong in a single-shot setting but chooses correctly when it thinks through its solution.
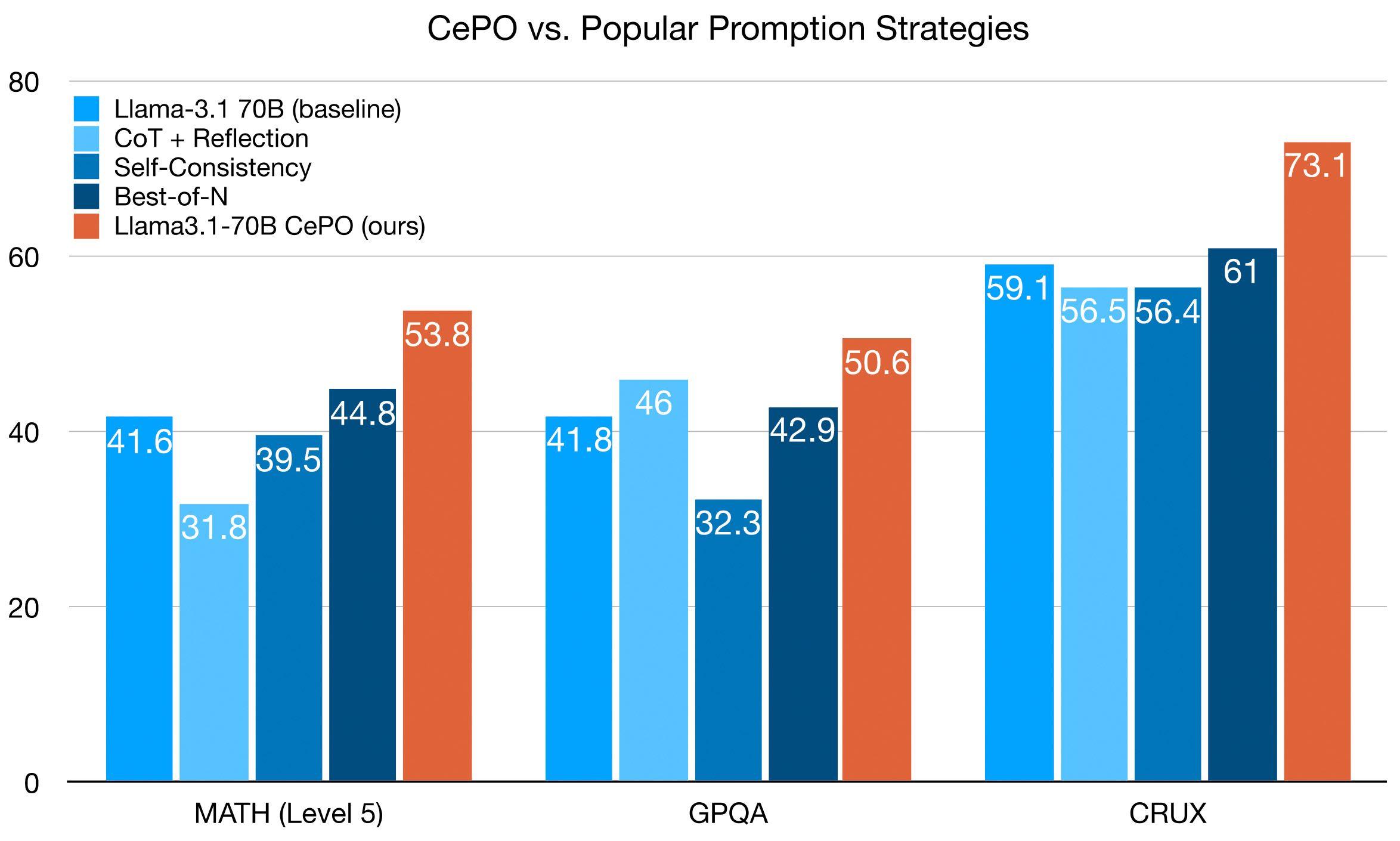
Comparison with Popular Prompting Strategies
Many researchers have explored inference-time techniques, with tools like optillm [10] making these methods accessible to practitioners. We evaluated three popular approaches from the literature:
CoT with Reflection [11]
- Uses structured reasoning with three phases
- <thinking>: Initial problem-solving strategy
- <reflection>: Review and adjust the plan
- <output>: Final solution
Self-Consistency [12]
- Generates multiple solutions
- Groups similar answers together
- Selects final answer based on the most common solution pattern
Best-of-N [13, 14]
- Simply generates N different solutions
- Picks the best one
While these methods show promise on specific tasks, they lack consistency across different types of problems. Our evaluation reveals that their performance varies significantly between tasks, and in some cases, they perform worse than the base model with no augmentation. By combining multiple approaches, CePO achieves consistent improvement across evals without regressions.
Conclusion
CePO demonstrates how test-time computation can significantly enhance Llama’s reasoning capabilities. Our next steps focus on three key areas:
- Advanced prompting frameworks that leverage comparative reasoning
- Synthetic data optimized for inference-time computation
- Enhanced verification mechanisms for complex reasoning chains
We will be open sourcing CePO to support community-driven development of inference-time optimization techniques. For updates on the release and to try CePO, follow us on Twitter or join our Discord.
Author: Pawel Filipczuk, Vithursan Thangarasa, Eric Huang, Amaan Dhada, Michael Wang, Rohan Deshpande, Emma Call, Ganesh Venkatesh
References
[1] https://openai.com/index/learning-to-reason-with-llms/
[2] Dubey, Abhimanyu, et al. The Llama 3 Herd of Models, arXiv preprint arXiv:2407.21783 (2024).
[3] https://huggingface.co/meta-llama/Llama-3.3-70B-Instruct
[4] Gu, Alex, et al. CRUXEval: A Benchmark for Code Reasoning, Understanding and Execution, arXiv preprint arXiv:2401.03065 (2024).
[5] Jain, Naman, et al. LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code, arXiv preprint arXiv:2403.07974 (2024).
[6] https://huggingface.co/datasets/AI-MO/aimo-validation-math-level-5
[7] Wang, Yubo, et al. MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark, arXiv preprint arXiv: 2406.01574 (2024).
[8] Rein, David, et al. GPQA: A Graduate-Level Google-Proof Q&A Benchmark, arXiv preprint arXiv: 2311.12022 (2023).
[9] https://openai.com/index/introducing-simpleqa/
[10] https://github.com/codelion/optillm
[11] Wei, Jason, et al. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, arXiv preprint arXiv:2201.11903 (2022).
[12] Wang, Xuezehi, et al. Self-Consistency Improves Chain of Thought Reasoning in Language Models, arXiv preprint arXiv:2203.11171 (2023).
[13] Stiennon, Nisan, et al. Learning to summarize from human feedback, arXiv preprint arXiv: 2009.01325 (2022).
[14] Nakano, Reiichiro, et al. WebGPT: Browser-assisted question-answering with human feedback, arXiv preprint arXiv:2112.09332 (2022).
[15] https://platform.openai.com/docs/models/gpt-4-and-gpt-4-turbo#gpt-4-turbo-andgpt-4