Tavus.io is an innovative AI video research company that specializes in APIs for building digital twin video experiences. Their cutting-edge Phoenix-2 model excels in generating lifelike replicas with synchronized facial movements and expressions, which can be applied to asynchronous video generation or real-time conversational video experiences.

The Challenge – creating a realistic conversation
In human conversations, delays longer than a few hundred milliseconds can make the interaction feel unnatural or disjointed. The quicker the system can complete each step—video analysis, speech recognition, LLM processing, and TTS—the more seamless and lifelike the conversation feels.
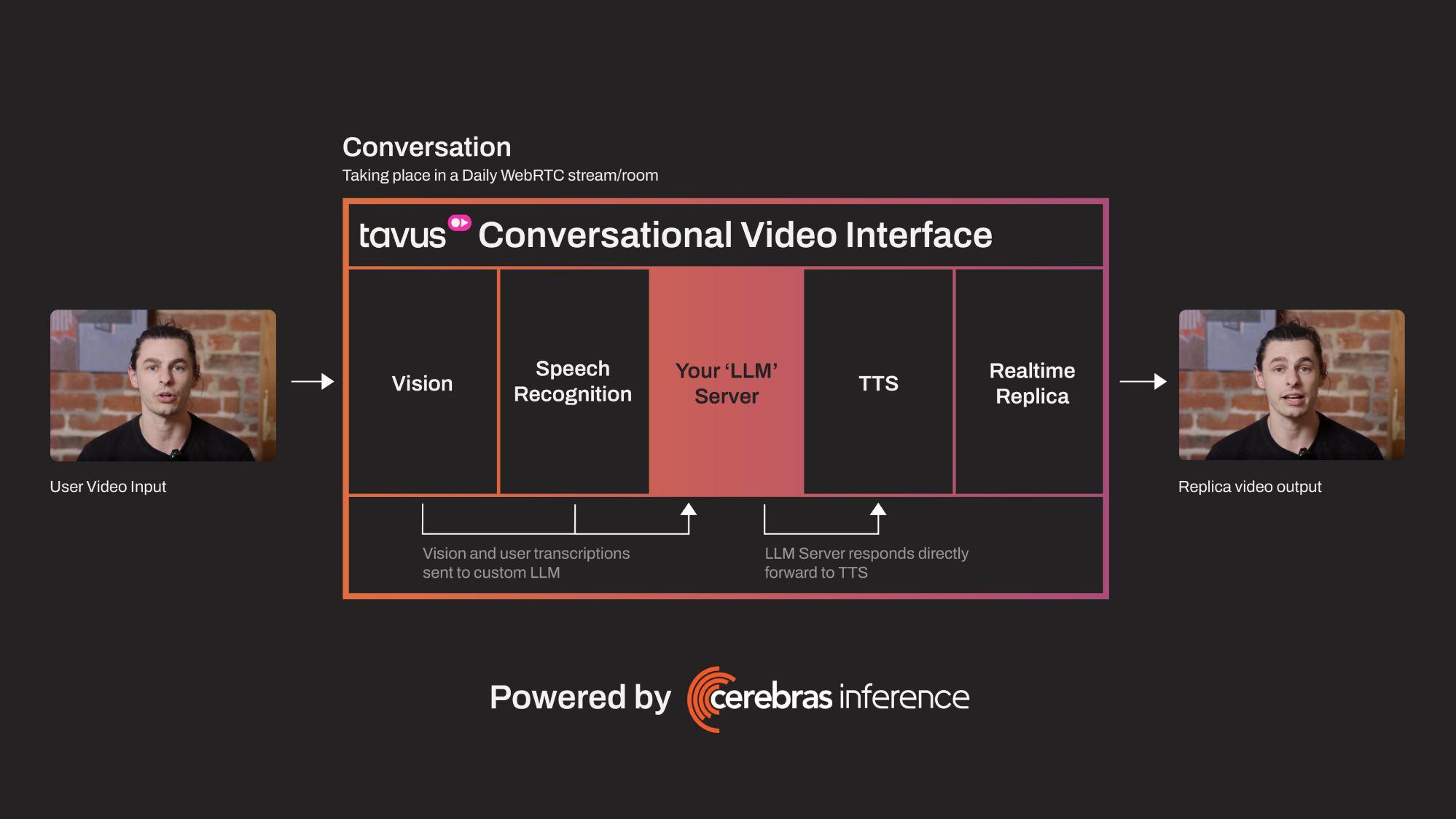
Tavus offers a highly optimized pipeline called a Conversational Video Interface (CVI). This pipeline brings together WebRTC, Vision models, Speech recognition models, LLMs, Text-to-speech models, and a high quality streaming replica powered by their custom Phoenix models.
Within the CVI pipeline, the LLM Chat completion is the longest part of the process, especially if it’s running on A100s, which still might introduce seconds of delay if not optimized. Since the LLM is responsible for generating the appropriate response, any delay here directly impacts how quickly the response can be delivered. Lowering latency here would significantly reduce the overall response time.
The delay in LLM response impacts all subsequent steps, like converting the text back to speech (TTS) and generating the video output with the replica. Any lag in the LLM step will be compounded by the additional steps that follow, further increasing the time between the user input and the video output.
In applications like Tavus, where you’re replicating a live person, the realism hinges on not just how accurate the content is but how responsive the system feels. A fast response time helps maintain the illusion of an interactive, real-time conversation.
Measuring overall LLM Latency in the end-to-end Conversational Video Interface (CVI) pipeline
For Tavus, both Time to First Token (TTFT) and Token Output Speed (TPS) are crucial for maintaining a natural conversation flow. The total LLM latency for Tavus’s CVI pipeline can be modeled as:
In this equation,
- Time to First Token (TTFT) represents the delay before the first token is generated, and minimizing this ensures the system responds quickly, which is vital for real-time interactions.
- Tokens per Second (TPS) determines how fast the remaining tokens are generated after the first one.
- The 20 reflects the minimum token length required before the output can be passed to the text-to-voice model, ensuring that Tavus can generate a coherent and complete audio response for the user.
Optimizing both TTFT and TPS is essential to reduce overall LLM latency.
The Solution – Powering realistic conversations with Cerebras’s fast inference
Tavus achieved a significant reduction in LLM latency by integrating Cerebras’s inference engine for their conversational video interface. Cerebras offers the fastest inference for the Llama 3.1-8B model, processing tokens at a rate of 2000 tokens per second (TPS) and with a Time to First Token (TTFT) of just 440 milliseconds.
By reducing the Time to First Token (TTFT) by 66%, Tavus was able to cut the initial response delay significantly, allowing the system to react faster to user input. This improvement directly impacted the overall conversational flow, especially in real-time, interactive scenarios. Additionally, increasing the Token Output Speed (TPS) by 300% allowed Tavus to generate the remaining tokens much faster, further reducing the time it took to complete longer responses.
In total, Tavus was able to reduce LLM latency by 100-1000%, resulting in more seamless interactions. This reduction in latency ensured that the end-to-end pipeline—from LLM context completion to text-to-speech (TTS) and video generation—operated smoothly, providing users with a more lifelike and responsive experience.
Summary of Improvements:
TTFT Reduction: 66%: 300ms -> 100ms
TPS Increase: 300%: 1/30ms -> 1/10ms
Overall LLM Latency Reduction: 100-1000%
By leveraging Cerebras’s fast inference capabilities, Tavus not only improved the speed of response generation but also enhanced the overall user experience by making interactions feel more natural and immediate. With these optimizations, Tavus continues to lead the field in hyper-personalized video experiences powered by advanced AI technologies.
Experience Cerebras’s super fast inference speeds at cloud.cerebras.ai.